




获得服务器API
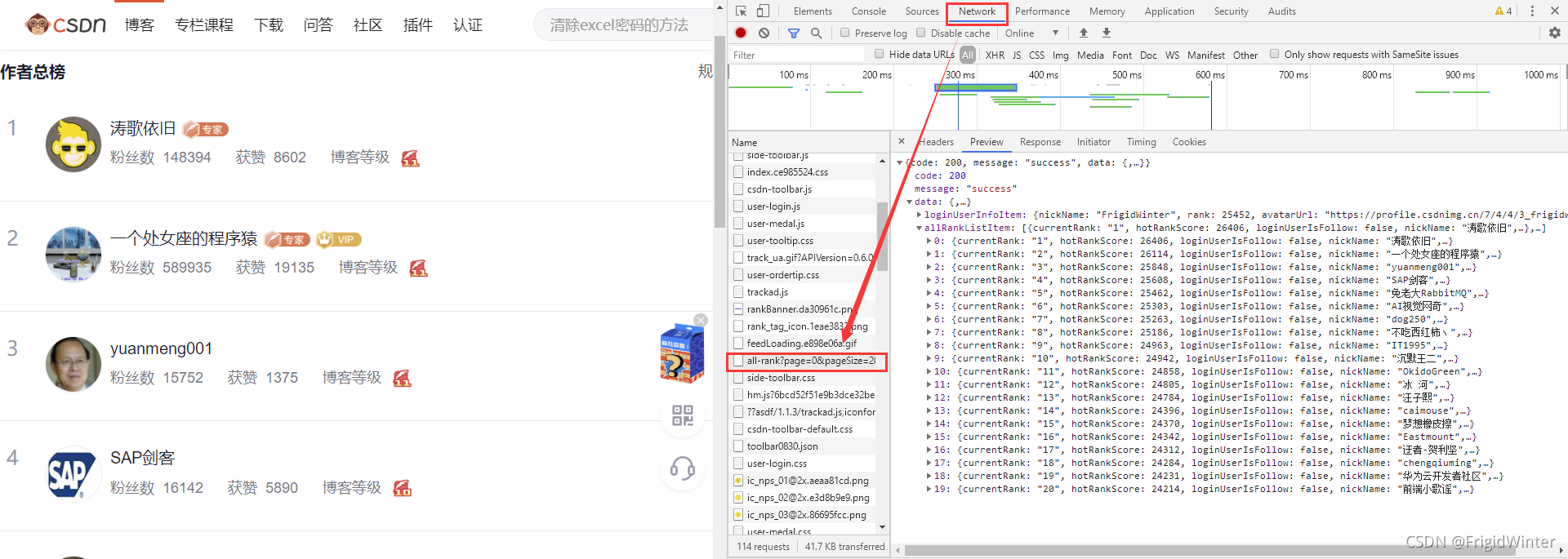
首先我们要知道通过什么接口可以获得网站数据:首先进入博客总榜,按F12进入控制台,选中Network选项卡监视网络请求,然后刷新网页。从下图可以看到在API"https://blog.csdn.net/phoenix/web/blog/all-rank?page=1&pageSize=20"中我们可以拿到我们想要的用户信息——主要是用户名
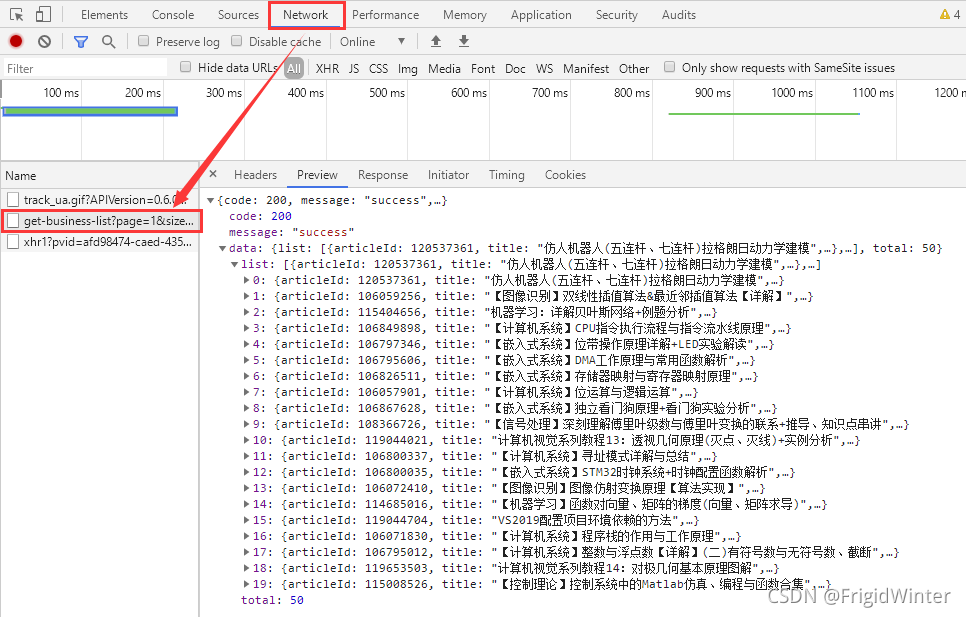
现在到用户博客首页,同样地,按F12进入控制台,选中Network选项卡监视网络请求,然后点击按访问量排序,则可以发现另一个关键APIhttps://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={},如下图所示。
我们与服务器的交互就依靠这两个API进行。
程序总体设计
思考一下,我们总共有如下的公共变量:
# 请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按访问量排行的文章列表
# 请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按访问量排行的文章列表
mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
userNames =[] # 用户名列表
titleList = [] # 文章标题列表
viewCntList = [] # 访问量列表
为便于管理,引入一个类进行爬虫,专门负责与服务器进行数据交互
class GetInfo:
def __init__(self) -> None:
# 请求头
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按访问量排行的文章列表
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = []
self.titleList, self.viewCntList = [], []
交互完成后,再使用别的库进行数据分析,将两个过程分离开
用户名爬取
定义一个私有的初始化函数
def __initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
这里获取用户名主要是为了动态生成第二个API
文章爬取
再定义一个私有函数,输入参数是用户名列表:
def __initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
titleList.extend(re.findall(r"\"title\":\"(.*?)\"", response.text))
viewCntList.extend(re.findall(r"\"viewCount\":(.*?),", response.text))
return titleList, viewCntList
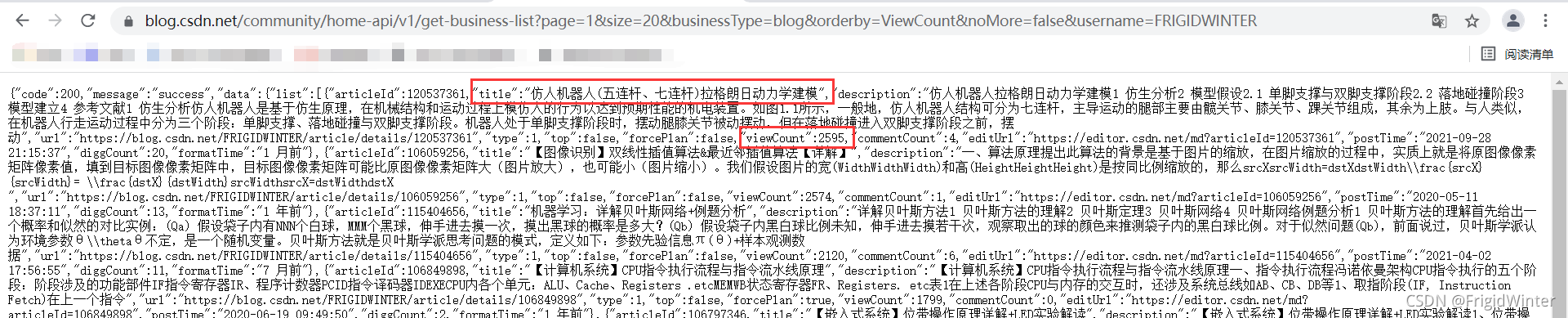
这里我使用正则表达式直接处理字符串,并返回文章标题列表、访问量列表。可以随便访问一个API做实验,这里以我的用户名为例,可以看到要获取文章标题就是以\"title\":\"(.*?)\"去匹配,其中\用于转义;要获取访问量就是以\"viewCount\":(.*?),去匹配,访问数字没有加引号。
事实上,用正则匹配不需要将返回的字符串加载为Json字典,可能有更快的处理效率(但不如json灵活)
这个爬虫类就设计好了,完整代码如下:
class GetInfo:
def __init__(self) -> None:
# 请求头
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按访问量排行的文章列表
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = self.__initRankUsrName()
self.titleList, self.viewCntList = self.__initArticalInfo(
self.userNames)
def __initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
titleList.extend(re.findall(r"\"title\":\"(.*?)\"", response.text))
viewCntList.extend(
re.findall(r"\"viewCount\":(.*?),", response.text))
return titleList, viewCntList
def __initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
info = GetInfo()
使用也很方便,只需要实例化调用其中的列表属性即可。
数据分析
数据存储
将文本数据存成csv格式,先设计表头:
if not os.path.exists("articalInfo.csv"):
#创建存储csv文件存储数据
with open('articalInfo.csv', "w", encoding="utf-8-sig", newline='') as f:
csv_head = csv.writer(f)
csv_head.writerow(['title', 'viewCnt'])
注意编码格式为utf-8-sig,否则会乱码
接下来存数据:
length = len(info.titleList)
for i in range(length):
if info.titleList[i]:
with open('articalInfo.csv', 'a+', encoding='utf-8-sig') as f:
f.write(info.titleList[i] + ',' + info.viewCntList[i] + '\n')
这样就可以了
小测试:智一面
http://www.gtalent.cn/exam/interview?token=66e1bed8fad81cf874ba26a9c35cafb0
http://www.gtalent.cn/exam/interview?token=300dc910e7f2af7f4c86b470280e0181

