NN(Namenode)的HA机制主要依靠zkfc完成,zkfc在NN所在节点以独立进程的方式运行。其内部主要由主控模块(ZKFailoverController)、健康检测模块(HealthMonitor)、主从选举模块(ActiveStandbyElector)三个模块协同实现。
zkfc进程启动时,首先会创建ZKFailoverController,负责其余两个模块回调事件的处理。
健康检测模块通过定时向NN发送rpc请求进行健康状态的监测。
主从选举模块封装了对zookeeper的处理逻辑,包括tcp连接的建立、创建节点、watch节点的变化等。
当NN的健康状态发生变化时,健康检测模块会回调通知主控模块,进而触发选举模块进行选举或者退出选举。
同样,当选举模块检测到zookeeper上节点的状态变化时,会自主触发进行选举,然后回调通知主控模块,最后通过rpc通知NN成为active或standby。
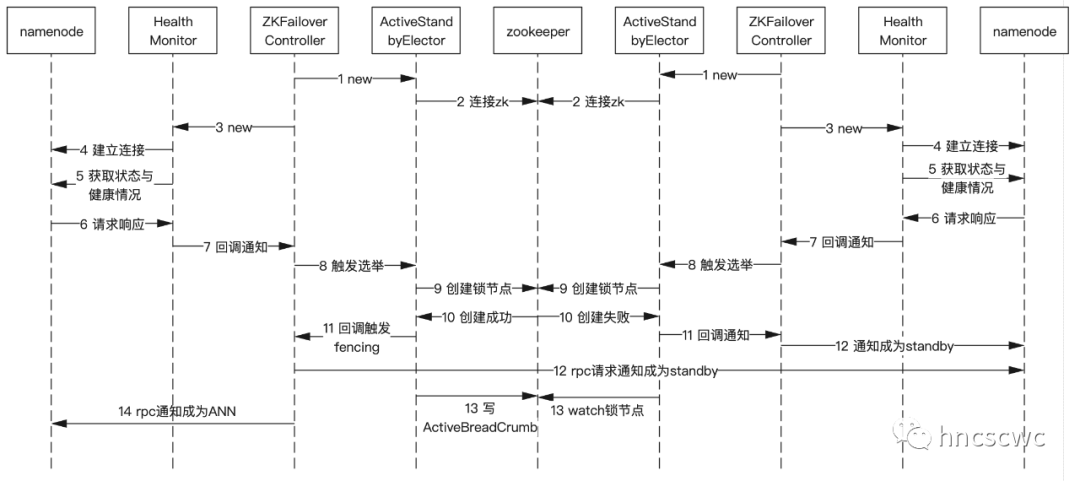
zkfc的启动选举流程如下图所示:
-
zkfc启动后,首先构造选举模块,并向zookeeper建立连接
-
然后启动对NN的健康检测,向NN发送rpc请求,获取NN的状态和健康情况
-
假如NN是健康的,触发进行选举,即在zookeeper上创建临时的锁节点
-
zk本身的机制保证只有一个zkfc能成功创建节点。
对于成功创建节点的zkfc,会向其他的NN发送rpc请求进行fencing(本质上是告知对端成为standby),然后在zookeeper上创建持久的记录NN主从相关信息的节点(ActiveBreadCrumb),最后向本地的 NN发送rpc请求告知其成为ANN(ActiveNameNode)。
而创建节点失败的zkfc,则通过回调向本地的NN发送rpc请求,告知其成为standby,然后对ANN在zookeeper中创建的锁节点进行watch。
【HA切换场景】
-
ANN异常
当ANN出现异常(包括进程退出,状态和健康情况的rpc请求无响应等)时,zkfc会主动退出选举,即结束与zookeeper的tcp连接,该连接对应的会话在zookeeper上创建的锁节点也会自动被删除。
在该节点上进行watch的(运行在SNN上的)zkfc感知到节点的变化,触发进行选举(重新在zookeeper上创建锁节点),然后获取ActiveBreadCrumb节点的值,从中得到老的ANN节点的信息,当发现老的ANN并非本节点时,zkfc就触发对其进行fencing,然后在ActiveBreadCrumb节点上写入新的信息,最后通知SNN成为新的ANN。
-
zkfc异常&ANN所在节点网络异常
这两种场景和上面的流程差别不大,区别在于,zookeeper检测zkfc建立的连接超时,从而自动将该连接上会话创建的临时节点删除。后面的流程就和上面的一样了。
【注意事项】
-
fencing的处理
前面选举流程和HA切换流程中都提到了fencing(隔离),那么为什么好进行fencing,fencing的意义是什么?
就上面zkfc异常的场景,来深入分析下:
当ANN所在节点的zkfc出现异常,或者仅仅是zkfc与zookeeper之间的网络不稳定,导致zkfc与zookeeper之间的会话超时,从而触发snn节点上的zkfc选举并成为新的ANN。
如果不进行fencing,那么此时存在两个ANN,并同时对外提供服务,这可能会导致hdfs的数据不能保证一致性,甚至出现错乱无法恢复。
因此SNN在成为新的ANN之前,需要对老的ANN进行fencing处理。
具体为zkfc直接向老的ANN发送rpc请求,通知其成为SNN,这个过程为优雅的fencing。
如果老的ANN成功响应,那么zkfc会进而通知SNN成为新的ANN。
如果老的ANN没有进行响应,那么就会根据配置的方式再次进行fencing。
可配置的方式包括ssh和执行指定的脚本。
ssh的方式为zkfc通过ssh到老的ANN节点上,然后执行kill动作,将老的ANN杀掉,最后通知SNN成为新的ANN。如果ANN所在节点的网络异常,无法成功ssh,因此也就无法将老的ANN杀掉。
因此,通常的方式是执行自己编写的脚本,在脚本中进行相关的处理动作。zkfc通过脚本的返回结果决定通知SNN成为新的ANN,或者再次触发选举流程。
-
健康状态的定义
前面提到了健康检测模块会定时向NN发送rpc请求,获取nn的状态(Active/Standby/Initializing)和健康状态,那么NN怎样判断自身是健康的呢?
跟踪其源码发现:NN对配置的本地目录(用于存储fsimage和editlog的目录和其他指定配置的目录)进行磁盘容量检查,如果目录对应的磁盘容量达到配置的最小值,则NN认为自身是健康的,否则认为是非健康的。
-
确保父节点存在
zkfc启动并成功连接zookeeper后,首先会存储锁节点的父亲节点是否存在,如果不存在,zkfc进程会直接退出。
zkfc启动时,可以指定format参数,这时zkfc会删除在zookeeper上存储的信息,并创建出必备的父亲节点,然后进程退出。再次启动时(不带参数)就能正确进行选举了。
另外,如果在zkfc运行过程中,将对应的父亲节点删除了,zkfc不会再自动创建出来,此时选举用的锁节点会持续创建失败导致无法正常选举,从而导致NN无法正常提供服务。
-
确保NN的ID与IP保持一致
NN正常选举成功后,ANN会在zookeeper上创建ActiveBreadCrumb节点,记录ANN/SNN的ID与对应的IP信息。
由于该节点是持久化的,因此当NN重启或者重新选举后,会读取该节点的值,从中获取老的ANN的IP信息,用于fencing处理。在此之前,会将节点记录的NN的ID与对应的IP和本地配置的情况进行比较,如果与配置中的不一致,会抛出异常不会再进行后续的处理。
通常出现该情况的场景是NN以容器的方式部署运行,当NN所在的容器下线重启后,NN分配的IP发生了变化,导致与记录在zookeeper中ActiveBreadCrumb节点的信息不一致。