初版:
ThreadPoolExecutor executor = new ThreadPoolExecutor(6, 6, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(200));
for (int j = 1; j <= 总页数; j++) {
executor.execute(()->{
// 1.抓取网页,获得图片url
// 2.根据url保存图片
// 3.保存后记录成功和失败的信息到本地txt
});
}
程序看起来没有什么问题,只开了6线程操作,开始没敢开太多线程,怕被网站拉黑。。
但是运行起来太慢了,一晚上只爬了10个多G,目前分析问题主要有两点:
1.并发操作本地txt,会拖慢单个任务执行的速度
2.线程没有充分利用
首先看下操作文件方法吧,所用方法来自NIO:
Files.write(log, attr.getBytes("utf8"), StandardOpenOption.APPEND);
通过查看源码发现,该方法会构造一个OutputStream去调用write方法,而write方法上有synchronized,多线程操作无疑会转为重量锁
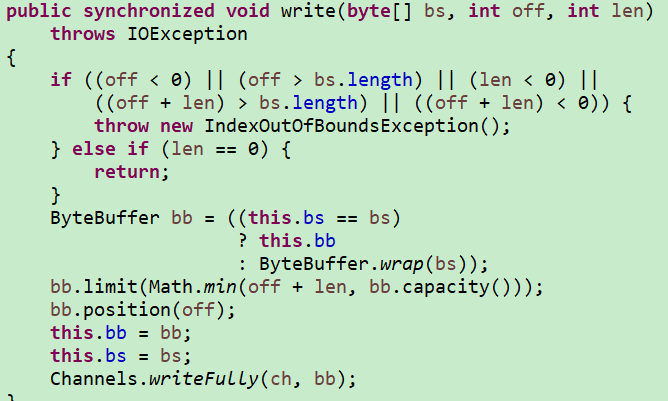
那么想要记录日志的话,最好是让它们没有线程竞争的情况下再去操作文件;
然后是优化多线程操作,相比于获取url,下载图片肯定是要比它更慢的,如果先统一获取url,然后根据url再去下载图片是否会更好?
第一次优化:
// 用于记录所有url
Queue<String> queue = new ConcurrentLinkedQueue<String>();
// 用于记录所有日志
Queue<String> logQueue = new ConcurrentLinkedQueue<String>();
// 所有任务
List<Consumer> allTasks = new ArrayList<>();
for (int j = 1; j <= 总页数; j++) {
allTasks.add(t ->{
// 获得url,放入queue中
});
}
// 使用ForkJoin并行执行记录url的任务
BatchTaskRunner.execute(allTasks, taskPerThread, tasks -> {
tasks.forEach(t->t.accept(null));
});
// 将所有url并行执行下载
List<String> list = queue.stream().collect(Collectors.toList());
BatchTaskRunner.execute(list, taskPerThread, tasks -> {
tasks.forEach(
// 1.下载文件
// 2.将url成功或失败放到logQueue中
);
});
// 最后再记录日志
logQueue.forEach(
// 将所有日志保存到本地txt中
);
这里主要分为三步:
1.并行执行任务,抓取url放入queue
2.并行执行下载,从queue中取url
3.从logQueue中保存日志到本地
分析:先是抓取所有url,然后再去并行执行保存;将保存日志放到最后,保存了图片后最后的日志反而无关紧要了,但是运行时候我发现还是存在问题:
我去,为什么一定要先放url再去处理啊!!放的同时也取任务,最后剩余的任务再并行执行不是更快!
好吧,有了这个想法,直接开干:
第二次优化:
/****************************第二次增加的逻辑start**************************************/
// 控制主线程执行
CountDownLatch countDownLatch = new CountDownLatch(totalPageSize);
// 用于消费queue的线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(12, 12, 0, TimeUnit.SECONDS, new SynchronousQueue<>());
// 用于自旋时的开关
volatile boolean flag = false;
/****************************第二次增加的逻辑end**************************************/
// 用于记录所有url
Queue<String> queue = new ConcurrentLinkedQueue<String>();
// 用于记录所有日志
Queue<String> logQueue = new ConcurrentLinkedQueue<String>();
// 所有任务
List<Consumer> allTasks = new ArrayList<>();
for (int j = 1; j <= 总页数; j++) {
allTasks.add(t ->{
// 获得url,放入queue中
});
}
// 开了一个线程去执行,主要是为了让它异步去操作
new Thread(()->{
// 使用ForkJoin并行执行记录url的任务
// finally中调用countDownLatch.countDown()
BatchTaskRunner.execute(allTasks, taskPerThread, tasks -> {
tasks.forEach(t->t.accept(null));
});
}).start();
// 一边抓取一边消费
for (int i = 0; i < 12; i++) {
executor.execute(()->{
try {
takeQueue(); // 从queue获得url并消费,如果信号量归零则将flag置为true
} catch (InterruptedException e) {
}
});
}
for(;;) {
if(flag) {
break;
}
Thread.sleep(10000);
}
countDownLatch.await();
executor.shutdownNow();
// 都取完了,就不必再去并行执行了
if(queue.size() == 0) {
return;
}
// 将所有url并行执行下载
List<String> list = queue.stream().collect(Collectors.toList());
BatchTaskRunner.execute(list, taskPerThread, tasks -> {
tasks.forEach(
// 1.下载文件
// 2.将url成功或失败放到logQueue中
);
});
// 最后再记录日志
logQueue.forEach(
// 将所有日志保存到本地txt中
);
其中的takeQueue方法逻辑:
void takeQueue() throws InterruptedException {
for(;;) {
long count = countDownLatch.getCount();
// 未归零则一直去消费
if(count > 0) {
String poll = queue.poll();
if(poll != null) {
consumer.accept(poll); // 根据url去下载
}else {
Thread.sleep(3000);
}
} else {
flag = true;
return;
}
}
}
大概撸了个逻辑,日志什么的已经不重要了。。。
主线程自旋,保存url同时去并发下载,如果保存url的逻辑执行完了队列中还有url,则并行去下载
看着线程都用上了,感觉爽多了

即使在消费,queue中对象还是越来越多