引言
对于池化层和步长为2的卷积层的思考源于前一段时间对于2.0文档API的评估。自从ResNet开始,大家逐渐使用步长为2的卷积层替代Size为2的池化层,二者都是对特征图进行下采样的操作。池化层的主要意义(目前的主流看法,但是有相关论文反驳这个观点)在于invariance(不变性),这个不变性包括平移不变性、尺度不变性、旋转不变形。其过程如下图所示。
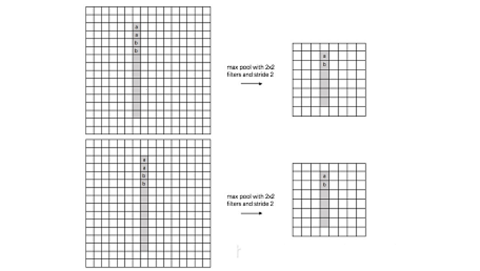
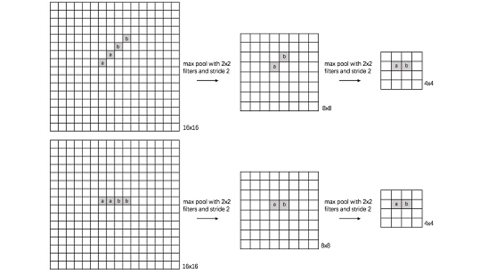

对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则;而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的。下面对两种下采样方式进行一组对比实验,实验设计的可能不够严谨,欢迎大家在评论区讨论。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
实验设计
本次对比实验采用LeNet进行对比,目的在于简单的说明池化层与步长为2的卷积层之前的区别。采用MNIST数据集。
1、导入paddle,使用2.0版本的paddle
import paddle
print(paddle.__version__)
2.0.0-rc0
2、导入训练数据和测试数据
train_dataset = paddle.vision.datasets.MNIST(mode='train')
test_dataset = paddle.vision.datasets.MNIST(mode='test')
3、查看数据
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))
4、构建LeNet5网络
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.max_pool2(x)
# print(x.shape)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
5、模型封装与配置
from paddle.metric import Accuracy
model2 = paddle.Model(LeNet()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model2.parameters())
# 配置模型
model2.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy(topk=(1, 2))
)
6、模型训练,这里进行10次迭代。
# 训练模型
model2.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1
)
7、验证模型
model2.evaluate(test_dataset, batch_size=64, verbose=1)
Eval begin...
step 157/157 [==============================] - loss: 1.4789e-05 - acc_top1: 0.9810 - acc_top2: 0.9932 - 3ms/step
Eval samples: 10000
{'loss': [1.4788801e-05], 'acc_top1': 0.981, 'acc_top2': 0.9932}
8、构建使用步长为2的卷积层替代池化层的LeNet5
import paddle.nn.functional as F
class LeNet_nopool(paddle.nn.Layer):
def __init__(self):
super(LeNet_nopool, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
# self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv4 = paddle.nn.Conv2D(in_channels=16, out_channels=16, kernel_size=3, stride=2)
# self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
# print(x.shape)
x = F.relu(x)
x = self.conv2(x)
# print(x.shape)
x = F.relu(x)
x = self.conv3(x)
# print(x.shape)
x = F.relu(x)
x = self.conv4(x)
# print(x.shape)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
9、模型配置与训练
from paddle.metric import Accuracy
model3 = paddle.Model(LeNet_nopool()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model3.parameters())
# 配置模型
model3.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy(topk=(1, 2))
)
# 训练模型
model3.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1
)
10、模型验证
model3.evaluate(test_dataset, batch_size=64, verbose=1)
Eval begin...
step 157/157 [==============================] - loss: 1.7807e-06 - acc_top1: 0.9837 - acc_top2: 0.9964 - 3ms/step
Eval samples: 10000
{'loss': [1.7806786e-06], 'acc_top1': 0.9837, 'acc_top2': 0.9964}
实验结果分析
从两者在MNIST测试集上的结果来看,使用步长为2的卷积层替代池化层,其模型的表现略高于原始的LeNet5。表明使用卷积层代替池化层是对模型表现有较好的提升。但是改进之后的LeNet5在参数量上是高于原始的LeNet5的,
11、参数量对比
#改进的LeNet5
print('# model3 parameters:', sum(param.numel() for param in model3.parameters()))
# model3 parameters: Tensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[66346])
#原始的LeNet5
, dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[66346])
```python
#原始的LeNet5
print('# model2 parameters:', sum(param.numel() for param in model.parameters()))
# model2 parameters: Tensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[61706])
总结
(1)从图像成像角度来看,图像在成像过程中接收模拟信号变成电信号再存储的阵列都不是同时的。即图片上每一点都是有时序的。结合图像的时域信息进行多模态训练可能会有突破。
(2)在图像中应用香农定理,下采样越多,信息丢失越多,对于CNN中池化层的讨论,大家可以参考:CNN真的需要下采样(上采样)吗?
(3)对于池化层不一样的看法,证伪:CNN中的图片平移不变性
(4)实际上已经有众多大佬对这个进行过论证,但是对于大家来说,自己动手永远比听别人讲来得更好,希望能和大家一起成长。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu