为了满足 GPT-3、CLIP 和 DALL+ 等大型模型的需要,以及类似于神经语言模型的缩放定律的快速小规模迭代研究,OpenAI 将基础设施 k8s 集群扩展到 7500 各节点。
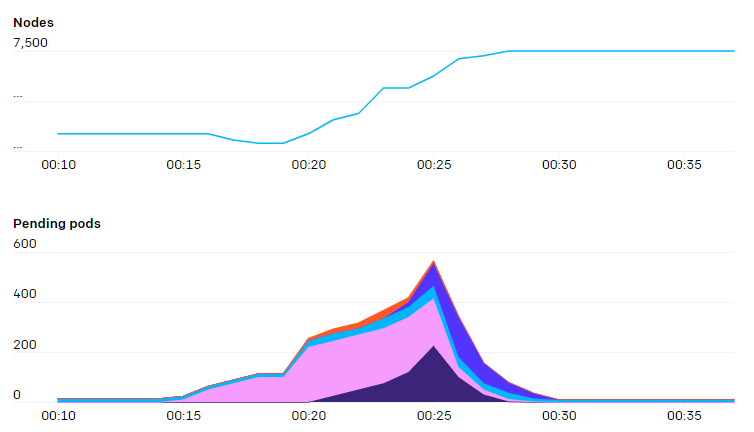
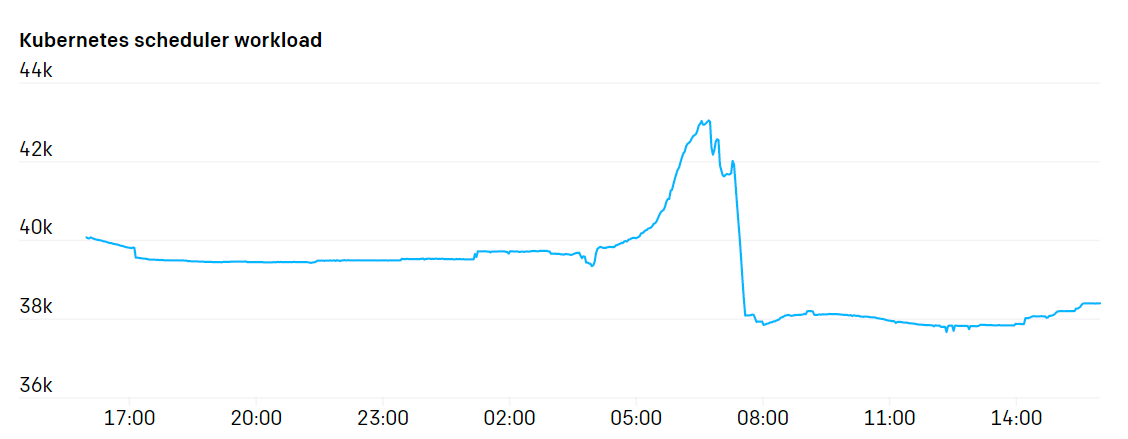
据其描述,对于大型机器学习作业来说,一个节点通常由单个 pod 占据,并且 OpenAI 部署的集群具有二等分带宽,因此尽管其有许多节点,但是调度程序的压力相对较低,仅在一项新任务一次性创建数百个 pod 时会有调度压力。
除此之外,OpenAI 还详细说明了其在扩展 k8s 集群时的重要工作内容,比如通过改用基于别名的 IP 寻址来解决大量节点的联网问题,在专用节点上部署 etcd 和 API 服务器以分散负载,定位使用 Prometheus 和 Grafana 收集指标时的 OOM 问题,设计对集群的健康检查,以及在团队中合理分配集群资源等。
不过,OpenAI 也指出,在扩展 k8s 集群时,目前仍有一些问题要解决,比如大规模时 Prometheus 的内置 TSDB 存储引擎压缩速度过慢,并且需要很长的时间才能重新启动 WAL(写入预录),以及扩展集群时,由于每个 pod 都会被计算为需要一定带宽而带来的网络带宽压力。然而,尽管还有很多地方需要改进,但 k8s 凭借其出色的扩展能力,仍然能满足其研究需求。