网络可以说是 Kubernetes 部署和使用过程中最容易出问题的了,最主要的是对网络技术非常熟悉的人员相对较少,和 Kubernetes 结合后能搞透彻网络这块的就更加稀少了,导致我们在部署使用过程中经常遇到一些网络问题。本文将重点关注网络,列出我们遇到的一些问题,包括解决和发现问题的简单方法,并就如何避免这些故障提供一些建议。
流量转发和桥接
Kubernetes 支持各种网络插件,每个插件出现问题的方式都不尽相同。
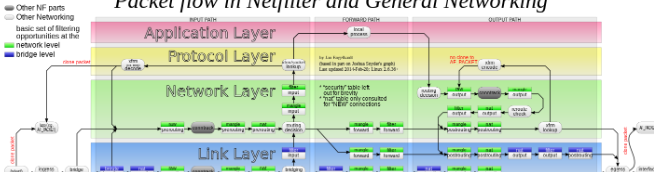
Kubernetes 的核心是依靠Netfilter内核模块来设置低级别的集群IP负载均衡,这需要用到两个关键的模块:IP 转发和桥接(IP forward 和 bridge)。
IP forward
IP forward 是一种内核态设置,允许将一个接口的流量转发到另外一个接口,该配置是 Linux 内核将流量从容器路由到外部所必须的。
失败情况
有时候该项设置可能会被安全团队运行的定期安全扫描给重置了,或者没有配置为重启后生效,在这种情况下,就会出现网络访问失败的情况。
Pod 服务连接超时:
* connect to 10.100.225.223 port 5000 failed: Connection timed out * Failed to connect to 10.100.225.223 port 5000: Connection timed out * Closing connection 0 curl: (7) Failed to connect to 10.100.225.223 port 5000: Connection timed out
Tcpdump可以显示发送了大量重复的SYN数据包,但没有收到ACK。
如何诊断
# 检查 ipv4 forwarding 是否开启 sysctl net.ipv4.ip_forward # 0 意味着未开启 net.ipv4.ip_forward = 0
如何修复
# this will turn things back on a live server sysctl -w net.ipv4.ip_forward=1 # on Centos this will make the setting apply after reboot echo net.ipv4.ip_forward=1 >> /etc/sysconf.d/10-ipv4-forwarding-on.conf # 验证并生效 sysctl -p
桥接
bridge-netfilter 设置可以使 iptables 规则可以在 Linux Bridges 上面工作,就像 Docker 和 Kubernetes 设置的那样。
此设置对于 Linux 内核进行宿主机和容器之间进行数据包的地址转换是必须的。
失败情况
Pod 进行外部服务网络请求的情况下,将会出现目标主机不可达或者连接拒绝等错误(host unreachable 或 connection refused)。
如何诊断
# 检查 bridge netfilter 是否开启 sysctl net.bridge.bridge-nf-call-iptables # 0 表示未开启 net.bridge.bridge-nf-call-iptables = 0
如何修复
# Note some distributions may have this compiled with kernel, # check with cat /lib/modules/$(uname -r)/modules.builtin | grep netfilter modprobe br_netfilter # 开启这个 iptables 设置 sysctl -w net.bridge.bridge-nf-call-iptables=1 echo net.bridge.bridge-nf-call-iptables=1 >> /etc/sysconf.d/10-bridge-nf-call-iptables.conf sysctl -p
防火墙规则
Kubernetes 提供了各种网络插件来支持其集群功能,同时也对传统的基于 IP 和端口的应用程序提供了向后兼容的支持。
最常见的 一种 Kubernetes 网络方案就是利用VxLan Overlay 网络,其中的 IP 数据包被封装在 UDP 中通过8472端口进行数据传输。
失败情况
这种情况下会出现100%数据包丢失:
$ ping 10.244.1.4 PING 10.244.1.4 (10.244.1.4): 56 data bytes ^C--- 10.244.1.4 ping statistics --- 5 packets transmitted, 0 packets received, 100% packet loss
如何诊断
最好的方式是使用相同的协议来传输数据,因为防火墙规则可能配置了特地的协议,比如可能会阻止 UDP 流量。
iperf是一个很好的验证工具:
# 在服务端执行 iperf -s -p 8472 -u # 在客户端执行 iperf -c 172.28.128.103 -u -p 8472 -b 1K
如何修复
当然是更新防火墙规则来停止组织这些流量了,这里有一些常见的 iptables 使用建议可以参考:
https://serverfault.com/questions/696182/debugging-iptables-and-common-firewall-pitfalls
Pod CIDR 冲突
Kubernetes 为容器和容器之间的通信建立了一层特殊的 Overlay 网络。使用隔离的 Pod 网络,容器可以获得唯一的 IP 并且可以避免集群上的端口冲突,我们可以点击这里查看更多关于 Kubernetes 网络模型的一些信息。
当 Pod 子网和主机网络出现冲突的情况下就会出现问题了。
失败情况
Pod 和 Pod 之间通信会因为路由问题被中断:
$ curl http://172.28.128.132:5000 curl: (7) Failed to connect to 172.28.128.132 port 5000: No route to host
如何诊断
首先查看分配的 Pod IP 地址:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE netbox-2123814941-f7qfr 1/1 Running 4 21h 172.28.27.2 172.28.128.103 netbox-2123814941-ncp3q 1/1 Running 4 21h 172.28.21.3 172.28.128.102 testbox-2460950909-5wdr4 1/1 Running 3 21h 172.28.128.132 172.28.128.101
然后将主机 IP 范围与apiserver中指定的 kubernetes 子网进行比较:
$ ip addr list 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 52:54:00:2c:6c:50 brd ff:ff:ff:ff:ff:ff inet 172.28.128.103/24 brd 172.28.128.255 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::5054:ff:fe2c:6c50/64 scope link valid_lft forever preferred_lft forever
如果出现了同网段的 IP,则很大概率会出现冲突了。
如何修复
仔细检查你的网络设置,确保你正在使用的网络、VLAN 或 VPC 之间不会有重叠。如果有冲突的,我们可以在 CNI 插件或 kubelet 的pod-cidr参数中指定 IP 地址范围,避免冲突。
故障排查工具
下面是一些我们在排查上述问题时使用的一些非常有用的工具。
tcpdump
Tcpdump是一个用来捕获网络流量的工具,可以帮助我们解决一些常见的网络问题,下面是一个使用 tcpdump 进行流量捕获的一个简单例子。
我们进入一个容器来尝试去和其他的容器进行通信:
kubectl exec -ti testbox-2460950909-5wdr4 -- /bin/bash $ curl http://172.28.21.3:5000 curl: (7) Failed to connect to 172.28.21.3 port 5000: No route to host
发现无法进行通信,然后在容器所在的主机,我们来捕获与容器目标 IP 有关的流量:
$ tcpdump -i any host 172.28.21.3 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes 20:15:59.903566 IP 172.28.128.132.60358 > 172.28.21.3.5000: Flags [S], seq 3042274422, win 28200, options [mss 1410,sackOK,TS val 10056152 ecr 0,nop,wscale 7], length 0 20:15:59.903566 IP 172.28.128.132.60358 > 172.28.21.3.5000: Flags [S], seq 3042274422, win 28200, options [mss 1410,sackOK,TS val 10056152 ecr 0,nop,wscale 7], length 0 20:15:59.905481 ARP, Request who-has 172.28.21.3 tell 10.244.27.0, length 28 20:16:00.907463 ARP, Request who-has 172.28.21.3 tell 10.244.27.0, length 28 20:16:01.909440 ARP, Request who-has 172.28.21.3 tell 10.244.27.0, length 28 20:16:02.911774 IP 172.28.128.132.60358 > 172.28.21.3.5000: Flags [S], seq 3042274422, win 28200, options [mss 1410,sackOK,TS val 10059160 ecr 0,nop,wscale 7], length 0 20:16:02.911774 IP 172.28.128.132.60358 > 172.28.21.3.5000: Flags [S], seq 3042274422, win 28200, options [mss 1410,sackOK,TS val 10059160 ecr 0,nop,wscale 7], length 0
我们可以看到由于线路出现了问题,所以内核无法将数据包路由到目标 IP。
这里有一篇关于 tcpdump 的一些比较有用的介绍文章:
http://bencane.com/2014/10/13/quick-and-practical-reference-for-tcpdump/
Netbox
在一个镜像中内置一些网络工具包,对我们排查工作会非常有帮助,比如在下面的简单服务中我们添加一些常用的网络工具包:iproute2 net-tools ethtool
FROM library/python:3.3 RUN apt-get update && apt-get -y install iproute2 net-tools ethtool nano CMD ["/usr/bin/python", "-m", "SimpleHTTPServer", "5000"]
这里是一个简单的 Deployment 的资源清单文件:
apiVersion: apps/v1beta1 kind: Deployment metadata: labels: run: netbox name: netbox spec: replicas: 2 selector: matchLabels: run: netbox template: metadata: labels: run: netbox spec: nodeSelector: type: other containers: - image: quay.io/gravitational/netbox:latest imagePullPolicy: Always name: netbox securityContext: runAsUser: 0 terminationGracePeriodSeconds: 30