各位少侠大家好!今天我们来聊聊 Java 并发下的乐观锁。
在聊乐观锁之前,先给大家复习一个概念:原子操作:
什么是原子操作呢?
我们知道,原子(atom)指化学反应不可再分的基本微粒。在 Java 多线程编程中,所谓原子操作,就是即使命令涉及多个操作,这些操作依次执行,不会被别的线程插队打断。
 原子操作
原子操作聊完原子操作了,我们进入正题。
大家都知道,一般而言,由于多线程并发会导致安全问题,针对变量的读和写操作,都会采用锁的机制。锁一般会分为乐观锁和悲观锁两种。
悲观锁
对于悲观锁,开发者认为数据发送时发生并发冲突的概率很大,所以每次进行读操作前都会上锁。
乐观锁
对于乐观锁,开发者认为数据发送时发生并发冲突的概率不大,所以读操作前不上锁。
到了写操作时才会进行判断,数据在此期间是否被其他线程修改。如果发生修改,那就返回写入失败;如果没有被修改,那就执行修改操作,返回修改成功。
乐观锁一般都采用 Compare And Swap(CAS)算法进行实现。顾名思义,该算法涉及到了两个操作,比较(Compare)和交换(Swap)。
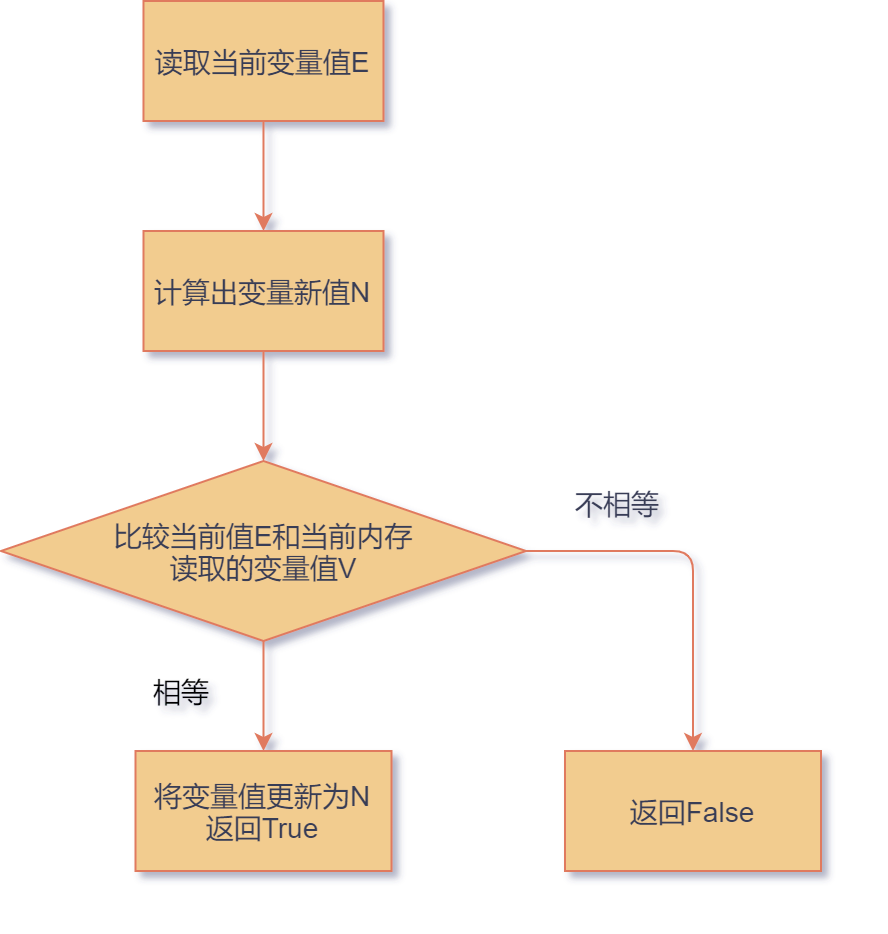 CAS 算法流程
CAS 算法流程CAS 算法的思路如下:
- 该算法认为不同线程对变量的操作时产生竞争的情况比较少。
- 该算法的核心是对当前读取变量值 E 和内存中的变量旧值 V 进行比较。
- 如果相等,就代表其他线程没有对该变量进行修改,就将变量值更新为新值 N。
- 如果不等,就认为在读取值 E 到比较阶段,有其他线程对变量进行过修改,不进行任何操作。
当线程运行 CAS 算法时,该运行过程是原子操作,也就是说,Compare And Swap 这个过程虽然涉及逻辑比较繁冗,但具体操作一气呵成。
Java中 CAS 的底层实现
Java 中的 Unsafe 类
我先问大家一个问题:
什么是指针?
针对学过 C、C++ 语言的同学想必都不陌生。说白了,指针就是内存地址,指针变量也就是用来存放内存地址的变量。
但对于指针这个东西的使用,有利有弊。有利的地方在于如果我们有了内存的偏移量,换句话说有了数据在内存中的存储位置坐标,就可以直接针对内存的变量操作;
弊端就在于指针是语言中功能强大的组件,如果一个新手在编程时,没有考虑指针的安全性,错误的操作指针把某块不该修改的内存值修改,容易导致整个程序崩溃。
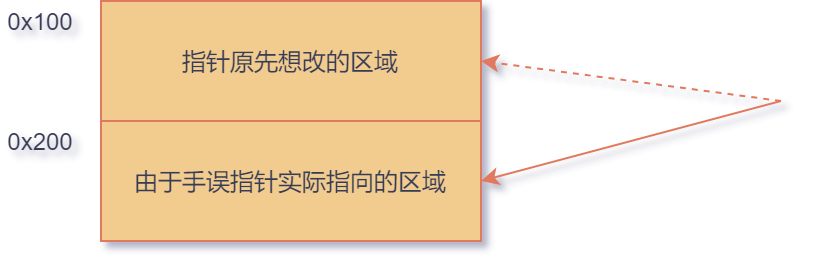 错误使用指针
错误使用指针对于 Java 语言,没有直接的指针组件,一般也不能使用偏移量对某块内存进行操作。这些操作相对来讲是安全(safe)的。
但其实 Java 有个类叫 Unsafe 类,这个类类使 Java 拥有了像 C 语言的指针一样操作内存空间的能力,同时也带来了指针的问题。这个类可以说是 Java 并发开发的基础。
Unsafe 类中的 CAS
一般而言,大家接触到的 CAS 函数都是 Unsafe 类提供的封装。下面就是一些 CAS 函数。
public final native boolean compareAndSwapObject(
Object paramObject1,
long paramLong,
Object paramObject2,
Object paramObject3);
public final native boolean compareAndSwapInt(
Object paramObject,
long paramLong,
int paramInt1,
int paramInt2);
public final native boolean compareAndSwapLong(
Object paramObject,
long paramLong1,
long paramLong2,
long paramLong3);
这就是 Unsafe 包下提供的 CAS 更新对象、CAS 更新 int 型变量、CAS 更新 long 型变量三个函数。
我们以最好理解的 compareAndSwapInt 为例,来看一下吧:
public final native boolean compareAndSwapInt(
Object paramObject,
long paramLong,
int paramInt1,
int paramInt2);
可以看到,该函数有四个参数:
- 第一个是目标对象
- 第二个参数用来表示我们上文讲的指针,这里是一个 long 类型的数值,表示该成员变量在其对应对象属性的偏移量。换句话说,函数就可以利用这个参数,找到变量在内存的具体位置,从而进行 CAS 操作
- 第三个参数就是预期的旧值,也就是示例中的 V。
- 第四个参数就是修改出的新值,也就是示例中的 N。
有同学会问了,Java 中只有整型的 CAS 函数吗?有没有针对 double 型和 boolean 型的 CAS 函数?
很可惜的是, Java 中 CAS 操作和 UnSafe 类没有提供对于 double 型和 boolean 型数据的操作方法。但我们可以利用现有方法进行包装,自制 double 型和 boolean 型数据的操作方法。
- 对于 boolean 类型,我们可以在入参的时候将 boolean 类型转为 int 类型,在返回值的时候,将 int 类型转为 boolean 类型。
- 对于 double 类型,则依赖 long 类型了, double 类型提供了一种 double 类型和 long 类型互转的函数。
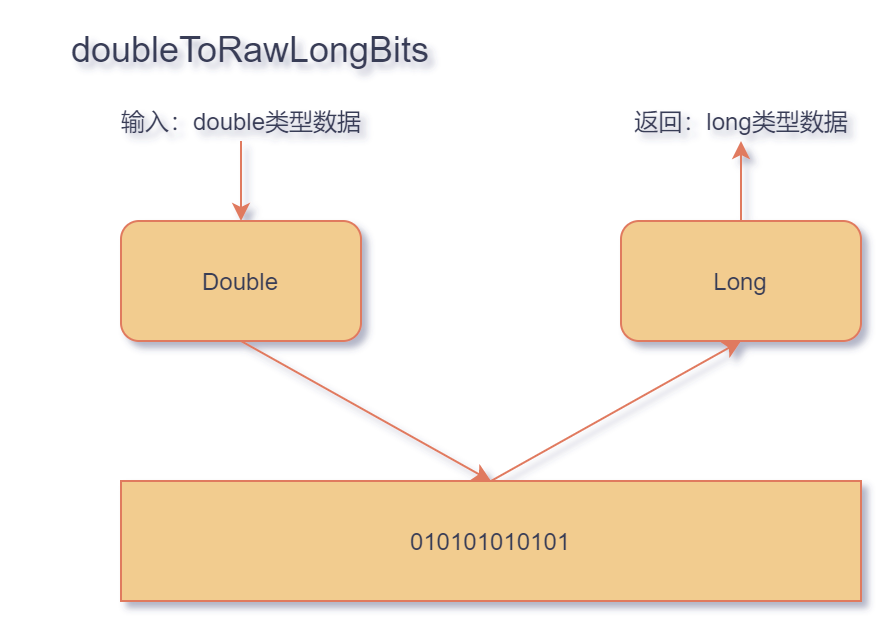
public static native double longBitsToDouble(
long bits);
public static native long doubleToRawLongBits(
double value);
大家都知道,基础数据类型在底层的存储方式都是bit类型。因此无论是long类型还是double类型在计算机底层存储方式都是比特。所以就很好理解这两个函数了:
-
longBitsToDouble 函数将 long 类型底层的实际二进制存储数据,用 double 类型强行翻译出来
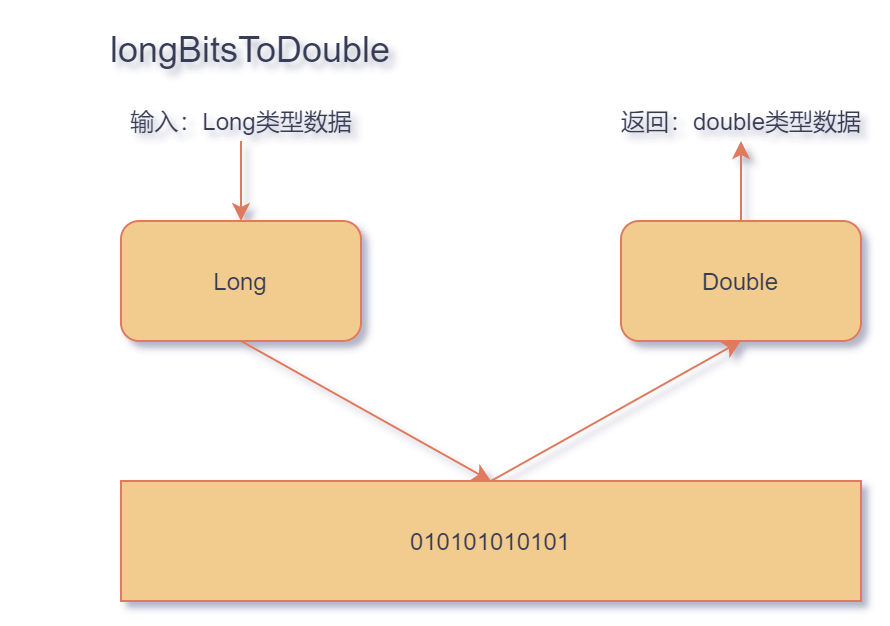
-
doubleToRawLongBits 函数将 double 类型底层的实际二进制存储数据,用 long 类型强行翻译出来
CAS 在 Java 中的使用
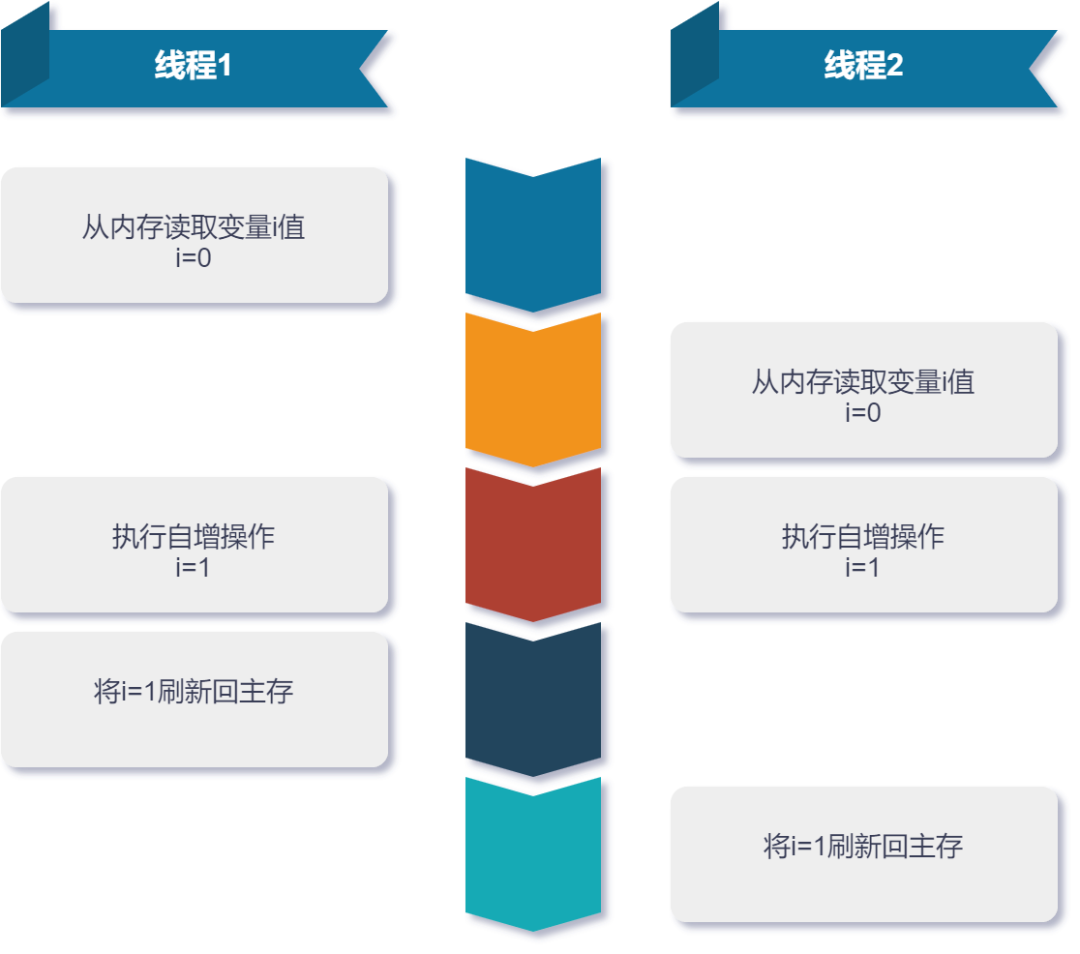
一个比较常见的操作,使用变量 i 来为程序计数,可以对 i 自增来实现。
int i=0;
i++;
但稍有经验的同学都知道这种写法是线程不安全的。
如果 500 个线程同时执行一次 i++,得到 i 的结果不一定为 500,可能会比 500 小。
这是因为 i++ 其实并不只是一行命令,它涉及以下几个操作:(以下代码为 Java 代码编译后的字节码)
getfield #从内存中获取变量 i 的值
iadd #将 count 加 1
putfield #将加 1 后的结果赋值给 i 变量
可以看到,简简单单一个自增操作涉及这三个命令,而且这些命令并不是一气呵成的,在多线程情况下很容易被别的线程打断。
 自增操作
自增操作虽然两个线程都进行了 i++ 的操作,i 的值本应是 2,但是按上图的流程来说,i 的值就变为 1 了
如果需要执行我们想要的操作,代码可以这样改写。
int i=0;
synchronized{
i++;
}
我们知道,通过 synchronized 关键字修饰时代价很大,Java 提供了一个 atomic 类,如果变量 i 被声明为 atomic 类,并执行对应操作,就不会有之前所说的问题了,而且相较 synchronized 代价较小。
AtomicInteger i= new AtomicInteger(0);
i.getAndIncrement();
Java 的 Atomic 基础数据类型类还提供
-
AtomicInteger针对 int 类型的原子操作 -
AtomicLong针对 long 类型的原子操作 -
AtomicBoolean针对 boolean 类型的原子操作
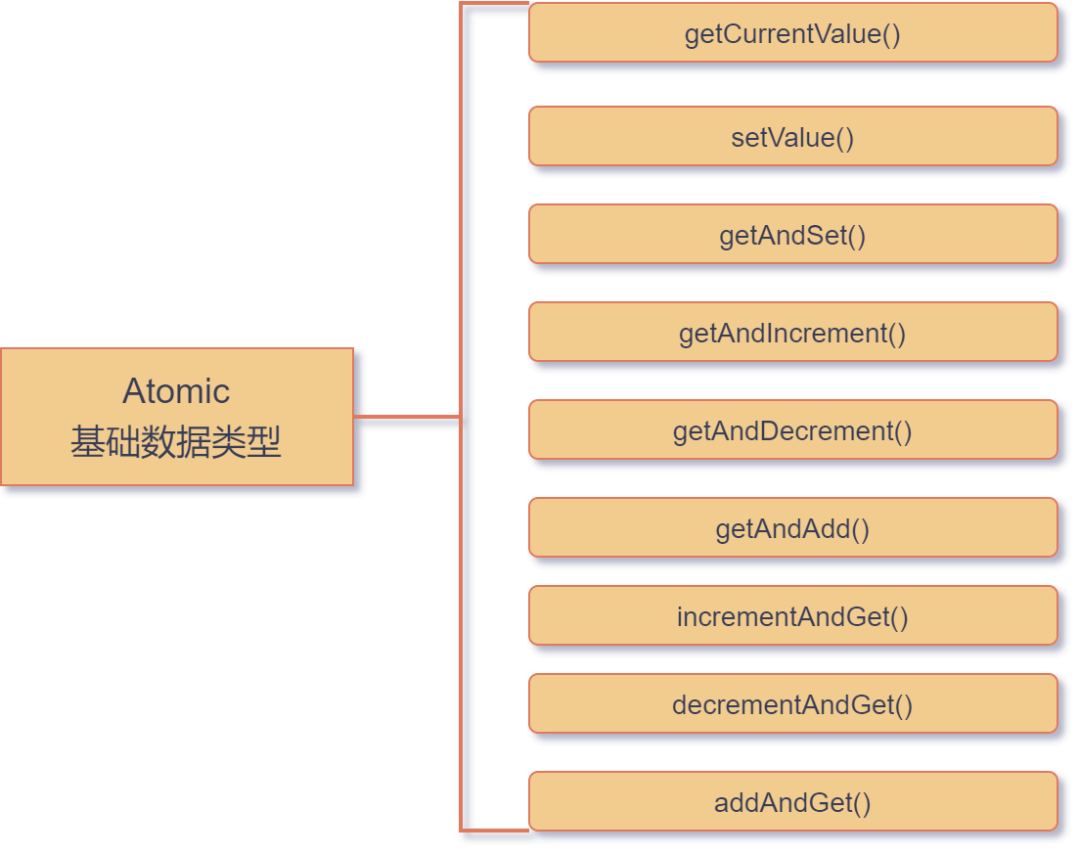
Atomic基础数据类型支持的方法如下图所示:
 Atomic基础数据类型
Atomic基础数据类型-
getCurrentValue:获取该基础数据类型的当前值。 -
setValue:设置当前基础数据类型的值为目标值。 -
getAndSet:获取该基础数据类型的当前值并设置当前基础数据类型的值为目标值。 -
getAndIncrement:获取该基础数据类型的当前值并自增 1,类似于 i++。 -
getAndDecrement:获取该基础数据类型的当前值并自减 1,类似于 i--。 -
getAndAdd:获取该基础数据类型的当前值并自增给定参数的值。 -
IncrementAndGet:自增 1 并获取增加后的该基础数据类型的值,类似于 ++i。 -
decrementAndGet:自减 1 并获取增加后的该基础数据类型的值,类似于 --i。 -
AddAndGet:自增给定参数的值并获取该基础数据类型自增后的值。
这些基本数据类型的函数底层实现都有 CAS 的身影。
我们来拿最简单的 AtomicInteger 的 getAndIncrement 函数举例吧:(源码来源 JDK 7 )
volatile int value;
···
public final int getAndIncrement(){
for(;;){
int current = get();
int next= current + 1;
if(compareAndSet(current, next))
return current;
}
}
这就类似之前的 i++ 自增操作,这里的 compareAndSet 其实就是封装了 Unsafe 类的一个 native 函数:
public final compareAndSet(int expect, undate){
return unsafe.compareAndSwapInt
(this, valueOffset, expect, update);
}
也就回到了我们刚刚讲述的 unsafe 包下的 compareAndSwapInt 函数了。
自旋
除了 CAS 之外,Atomic 类还采用了一种方式优化拿到锁的过程。
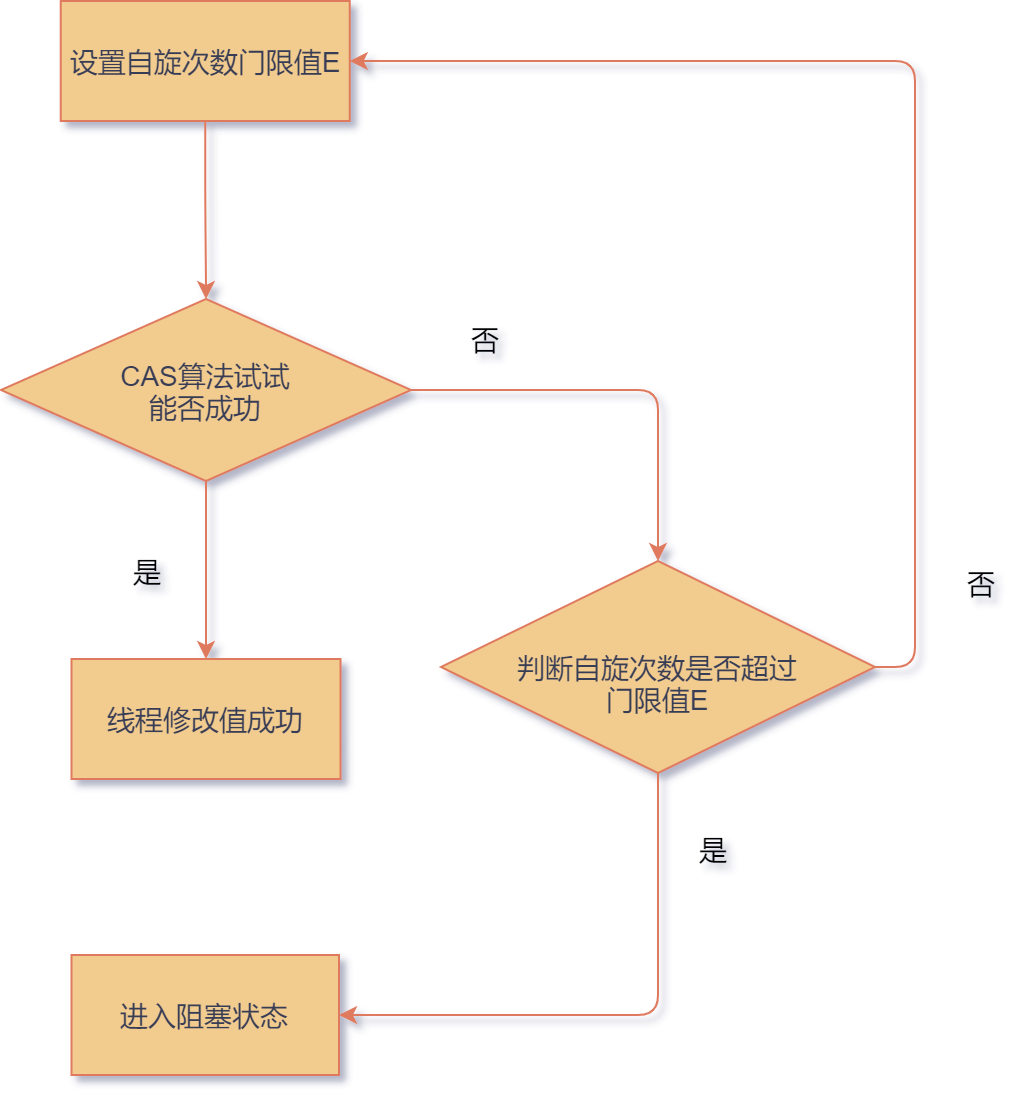
我们知道,当一个线程拿不到对应的锁的时候,可以有两种策略:
策略 1:放弃获得 CPU ,将线程置于阻塞状态,等待后续被操作系统唤醒和调度。
当然这么做的弊端很明显,这种状态的切换涉及到了用户态到内核态的切换,开销一般比较大,如果线程很快就把占用的锁释放了,这么做显然是不合算的。
策略 2:不放弃 CPU ,不停的重试,这种操作也称为自旋。
当然这么做也有弊端,如果某个线程持有锁的时间过长,就会导致其它等待获取锁的线程一直在毫无意义的消耗 CPU 资源。使用不当会造成 CPU 使用率极高。在这种情况下,策略 1 更合理一些。
我们前文中所说的 AtomicInteger,AtomicLong 在执行相关操作的时候就采取策略 2。一般这种策略也被称为自旋锁。
可以看到在 AtomicInteger 的 getAndIncrement 函数中,函数外包了一个
for(;;)
其实就是一个不断重试的死循环,也就是这里说的自旋。
但现在大多采取的策略是开发者设置一个门限值,在门限值内进行不断地自旋。
如果自旋失败次数超过门限值了,那就采取进入阻塞状态。
 自旋
自旋ABA 问题与 AtomicMarkable
CAS 算法本身有一个很大的缺陷,那就是 ABA 问题。
我们可以看到, CAS 算法是基于值来做比较的,如果当前有两个线程,一个线程将变量值从 A 改为 B ,再由 B 改回为 A ,当前线程开始执行 CAS 算法时,就很容易认为值没有变化,误认为读取数据到执行 CAS 算法的期间,没有线程修改过数据。
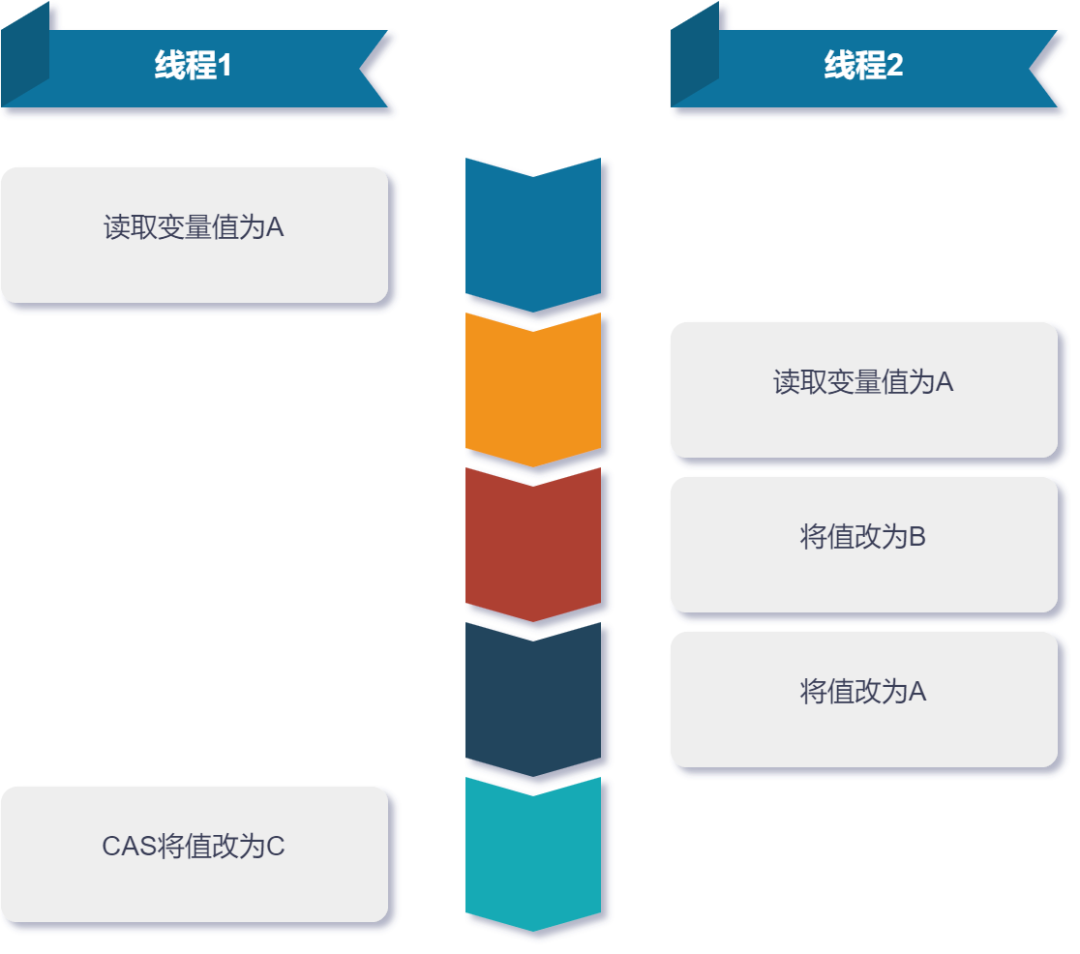 ABA 问题
ABA 问题咋一看好像这个缺陷不会引发什么问题,实则不然,给大家举个例子吧。
假设小艾银行卡有 100 块钱余额,且假定银行转账操作就是一个单纯的 CAS 命令,对比余额旧值是否与当前值相同,如果相同则发生扣减/增加,我们将这个指令用
CAS(origin,expect)表示。于是,我们看看接下来发生了什么:
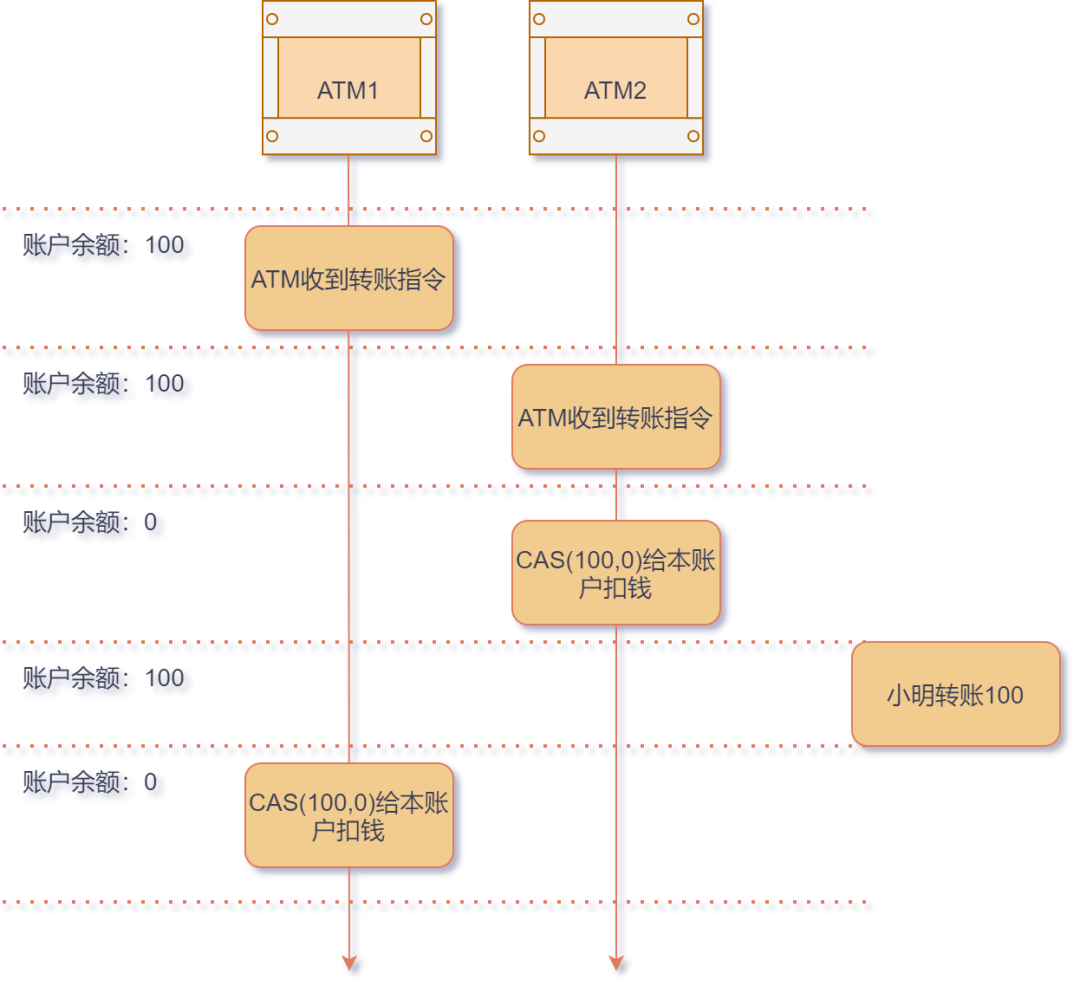 银行转账
银行转账-
小明欠小艾100块钱,小艾欠小牛100块钱,
-
小艾在 ATM 1号机上打算 转账 100 块钱给小牛;假设银行转账底层是用CAS算法实现的。由于ATM 1号机突然卡了,这时候小艾跑到旁边的 ATM 2号机再次操作转账;
-
ATM 2号机执行了 CAS(100,0),顺顺利利地完成了转账,此时小艾的账户余额为 0;
-
小明这时候又给小艾账上转了 100,此时小艾账上余额为 100;
-
这时候 ATM 1 网络恢复,继续执行 CAS(100,0),居然执行成功了,小艾账户上余额又变为了 0;
可怜的小艾,由于 CAS 算法的缺陷,让他损失了100块钱。

解决 ABA 问题的方法也不复杂,对于这种 CAS 函数,不仅要比较变量值,还需要比较版本号。
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
之前的 CAS 只有两个参数,带上版本号比较的 CAS 就有四个参数了,其中 expectedReference 指的是变量预期的旧值, newReference 指的是变量需要更改成的新值, expectedStamp 指的是版本号的旧值, newStamp 指的是版本号新值。
修改后的 CAS 算法执行流程如下图:
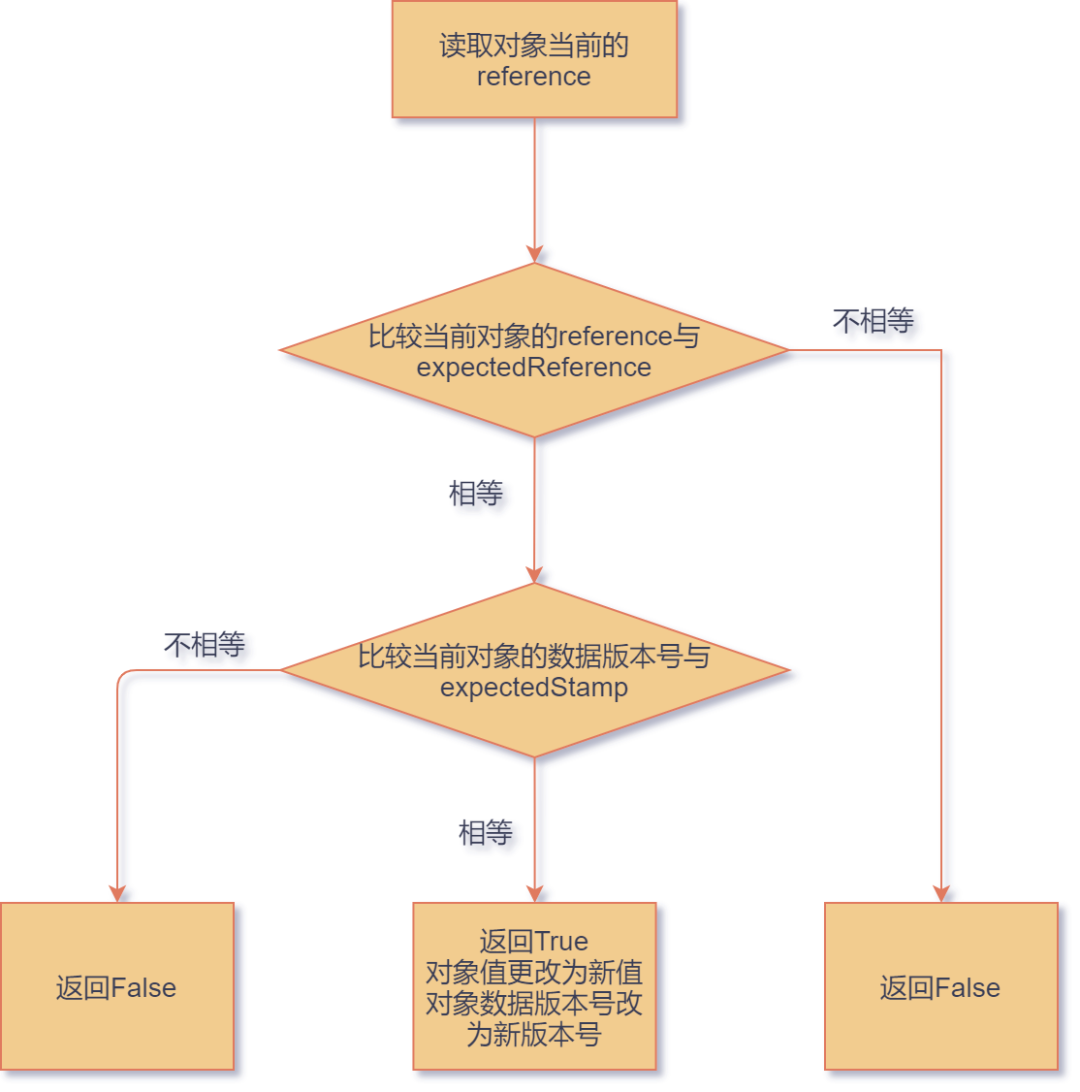 改正 CAS 算法
改正 CAS 算法AtomicStampedReference
那如何能在 Java 中顺畅的使用带版本号比较的 CAS 函数呢?
Java 开发人员都帮我们想好了,他们提供了一个类叫做 Java 的 AtomicStampedReference ,该类封装了带版本号比较的 CAS 函数,一起来看看吧。
AtomicStampedReference 定义在 java.util.concurrent.atomic 包下。
下图描述了该类对应的几个常用方法:
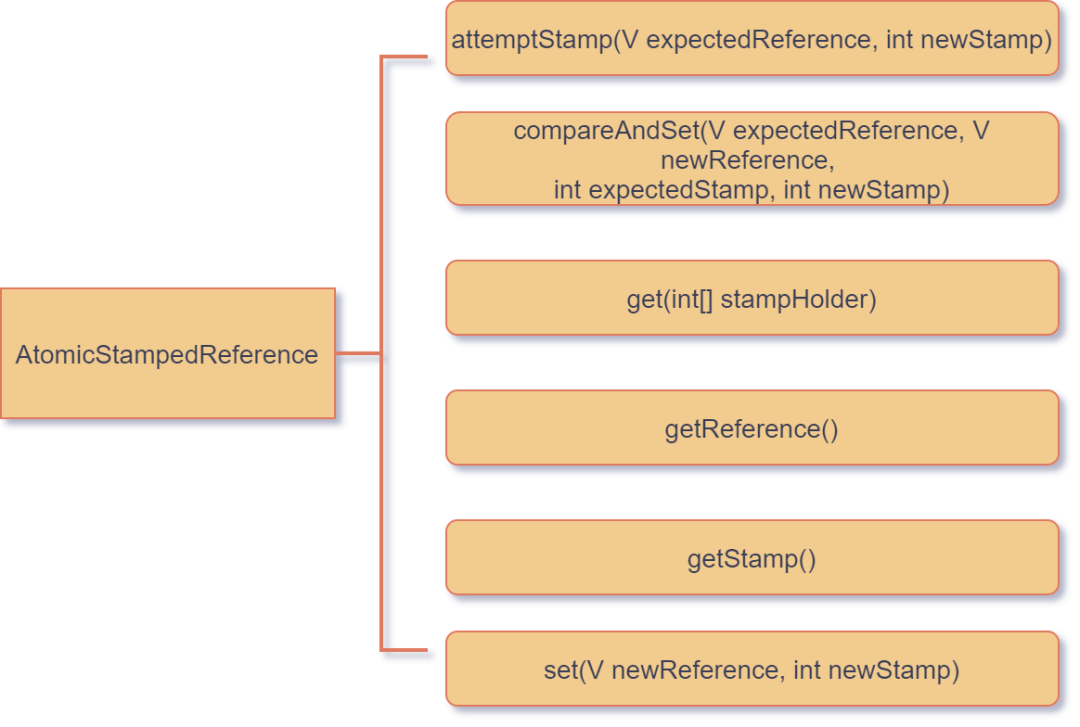 AtomicStampedReference
AtomicStampedReference-
attemptStamp:如果expectReference和目前值一致,设置当前对象的版本号戳为newStamp -
compareAndSet:该方法就是前文所述的带版本号的 CAS 方法。 -
get:该方法返回当前对象值和当前对象的版本号戳 -
getReference:该方法返回当前对象值 -
getStamp:该方法返回当前对象的版本号戳 -
set:直接设置当前对象值和对象的版本号戳