
文章概要
一 前期准备工作
1.1 在master节点创建NFS共享目录
# 在master创建共享目录
[bigdata@k8s-master ~]$ sudo mkdir -p /data/{zookeeper,kafka}
# 在master执行授权
[bigdata@k8s-master ~]$ sudo chown -R 755 /data/{zookeeper,kafka}
# 修改配置文件
[bigdata@k8s-master ~]$ sudo vi /etc/exports
/data/zookeeper *(rw,sync,no_root_squash)
/data/kafka *(rw,sync,no_root_squash)
# 使配置生效
[bigdata@k8s-master ~]$ sudo exportfs -r
# 检查配置是否生效
[bigdata@k8s-master ~]$ sudo exportfs
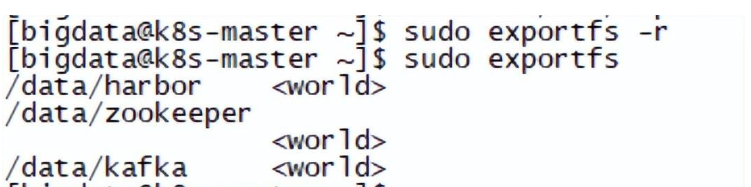
sudo exportfs
1.2 在所有的node节点挂载共享目录
在所有的客户端节点挂载NFS目录
[bigdata@k8s-node1 ~]$ sudo mkdir -p /data/{zookeeper,kafka}
[bigdata@k8s-node1 ~]$ sudo mount -t nfs k8s-master:/data/zookeeper /data/zookeeper
[bigdata@k8s-node1 ~]$ sudo mount -t nfs k8s-master:/data/kafka /data/kafka
# 验证是否挂载成功
[bigdata@k8s-node1 ~]$ df -h
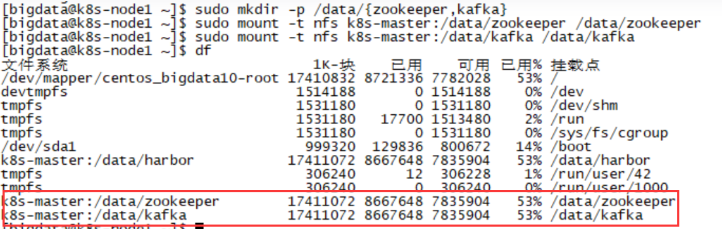
挂载NFS目录
配置开机自动挂载
[bigdata@k8s-node1 ~]$ sudo vi /etc/fstab
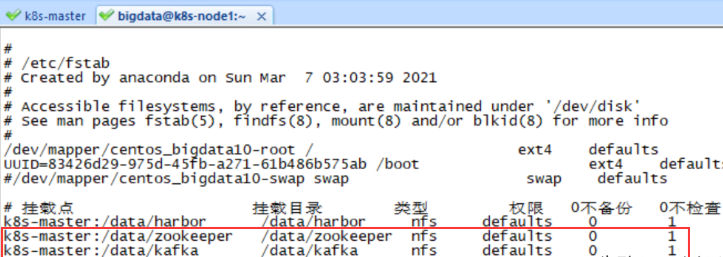
开机自动挂载
1.3 创建zookeeper的持久化存储
1.3.1 准备zookeeper-nfs-storage.yaml文件
创建用作zookeeper集群的持久化存储(zookeeper-nfs-storage),并将其放到/opt/module/zookeeper目录,不存在需创建。
# 创建一个NFS存储类
# 源自class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: zookeeper-nfs-storage # 改名
namespace: zookeeper
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
# 删除pv的时候,pv的内容是否要备份
archiveOnDelete: "false"
# 存储卷绑定策略
volumeBindingMode: Immediate
# 是否允许扩容
allowVolumeExpansion: true
---
# 源自rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
# 源自:deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zookeeper
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 # 阿里云地址
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes # 容器内挂载点
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.220.101 # 指定nfs服务器地址
- name: NFS_PATH
value: /data/zookeeper # 指定nfs服务器的共享目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.220.101
path: /data/zookeeper
1.3.2 创建zookeeper的SC存储
[bigdata@k8s-master module]$ pwd
/opt/module
[bigdata@k8s-master module]$ mkdir zookeeper
[bigdata@k8s-master module]$ cd zookeeper
[bigdata@k8s-master zookeeper]$ kubectl create namespace zookeeper
[bigdata@k8s-master zookeeper]$ kubectl apply -f zookeeper-nfs-storage.yaml
[bigdata@k8s-master zookeeper]$ kubectl get sc -n zookeeper
[bigdata@k8s-master zookeeper]$ kubectl describe sc zookeeper-nfs-storage -n zookeeper
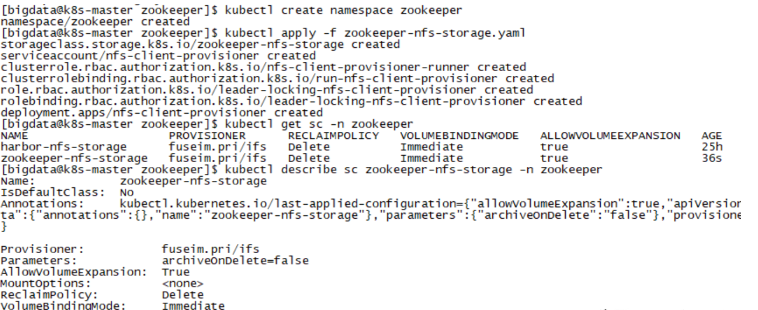
zookeeper的SC存储
1.4 创建kafka的持久化存储
1.4.1 准备kafka-nfs-storage.yaml文件
创建用作kafka集群的持久化存储(kafka-nfs-storage),并将其放到/opt/module/kafka目录,不存在需创建。
# 创建一个NFS存储类
# 源自class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: kafka-nfs-storage # 改名
namespace: kafka
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
# 删除pv的时候,pv的内容是否要备份
archiveOnDelete: "false"
# 存储卷绑定策略
volumeBindingMode: Immediate
# 是否允许扩容
allowVolumeExpansion: true
---
# 源自rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
# 源自:deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kafka
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 # 阿里云地址
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes # 容器内挂载点
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.220.101 # 指定nfs服务器地址
- name: NFS_PATH
value: /data/kafka # 指定nfs服务器的共享目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.220.101
path: /data/kafka
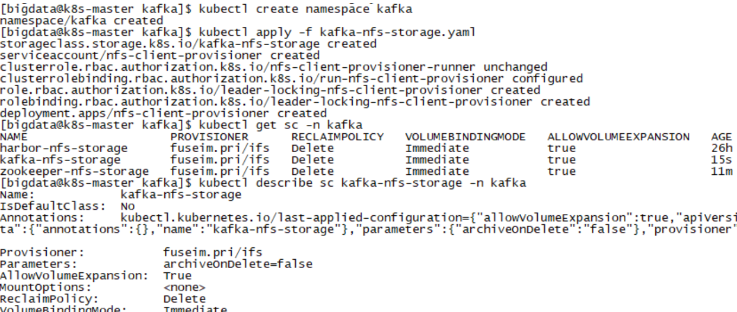
1.4.2 创建Kafka的SC存储
[bigdata@k8s-master zookeeper]$ cd ..
[bigdata@k8s-master module]$ mkdir kafka
[bigdata@k8s-master module]$ cd kafka/
[bigdata@k8s-master kafka]$ touch kafka-nfs-storage.yaml
[bigdata@k8s-master kafka]$ kubectl create namespace kafka
[bigdata@k8s-master kafka]$ kubectl apply -f kafka-nfs-storage.yaml
[bigdata@k8s-master kafka]$ kubectl get sc -n kafka
[bigdata@k8s-master kafka]$ kubectl describe sc kafka-nfs-storage -n kafka
zookeeper的SC存储
二 zookeeper on k8s 部署
2.1 选择Zookeeper的仓库地址
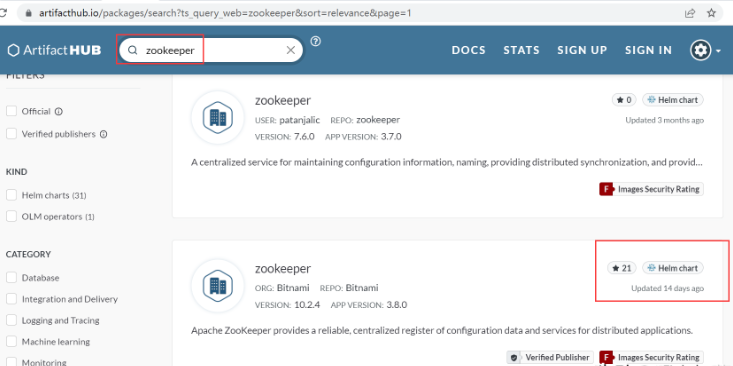
如何使用 helm 安装Zookeeper,helm 必须要知道从哪些仓库可以下载Zookeeper,有一个非常实用的网站https://artifacthub.io/,可以帮我们选择使用哪个仓库。选择stars数量最多的镜像源 bitnami/zookeeper。
artifacthub.io
既然选好了镜像源,需要将镜像源添加到本地。
2.1.1 添加镜像源
# 添加镜像源
[bigdata@k8s-master zookeeper]$ helm repo add bitnami https://charts.bitnami.com/bitnami
2.1.2 如何选择Zookeeper版本
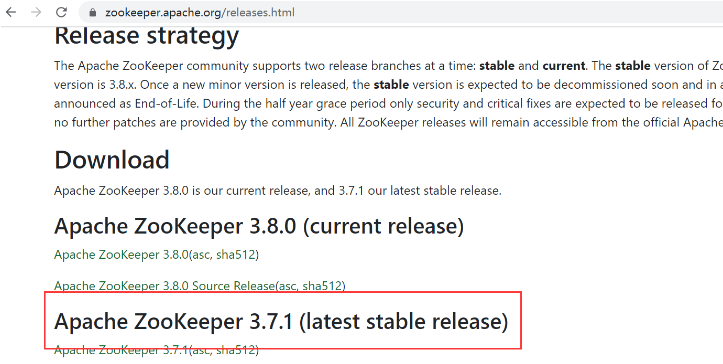
在大数据领域,通常都是优先选择稳定的版本,不追求最新版本。可以登录到zookeeper.apache.org网站上查看,目前zookeeper3.7.1是最新稳定版本。
zookeeper3.7.1
可以通过下面的命令,查找zookeeper版本,左侧是Chart版本,右侧是Zookeeper版本;只能根据Chart版本安装Zookeeper。
[bigdata@k8s-master zookeeper]$ helm search repo bitnami/zookeeper -l
zookeeper3.7.1
2.1.3 下载Zookeeper3.7
通过查询,发现zookeeper3.7.x系列最大的Chart version是8.1.2,因此,我们选择下载version8.1.2
# 下载
[bigdata@k8s-master zookeeper]$ helm pull bitnami/zookeeper --version 8.1.2
# 解压
[bigdata@k8s-master zookeeper]$ tar -zxvf zookeeper-8.1.2.tgz
2.2 修改配置信息
主要是修改values.yaml文件,values.yaml文件内容比较多,我只列出需要修改的部分。
image:
# 修改为本地的harbor地址
registry: 192.168.220.101:30002
# 修改成本地仓库
repository: bigdata/zookeeper
tag: 3.7.0-debian-10-r320
# Zookeeper Node节点副本数
replicaCount: 3
service:
# 将type类型改为NodePort
type: NodePort
ports:
# NodePort 范围 30000-32767
client: 32181
tls: 32182
persistence:
# 修改为zookeeper-nfs-storage.yaml metadata.name对应的值
storageClass: "zookeeper-nfs-storage"
# Enable Prometheus to access ZooKeeper metrics endpoint
metrics:
enabled: true
2.3 下载zookeeper
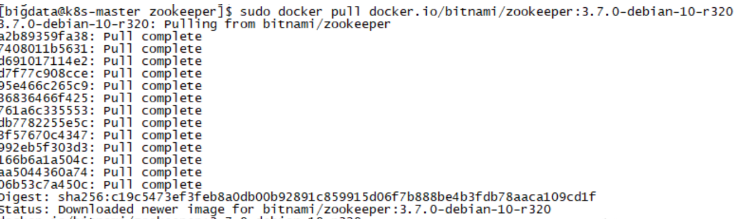
每个大公司都有自己的harbor仓库,存储镜像源。我们先pull一份
zookeeper:3.7.0-debian-10-r320镜像,然后push到本地harbor中。
这样做的好处是,① 可以在本地建立镜像版本库;② 通常公司的集群不能访问外网,可以直接从私有的harbor中下载镜像;③ 外网不稳定,有些镜像在国外,下载不到。
[bigdata@k8s-master zookeeper]$ sudo docker pull docker.io/bitnami/zookeeper:3.7.0-debian-10-r320
[bigdata@k8s-master zookeeper]$ sudo docker tag docker.io/bitnami/zookeeper:3.7.0-debian-10-r320 192.168.220.101:30002/bigdata/zookeeper:3.7.0-debian-10-r320
# 上传到本地Harbor
[bigdata@k8s-master zookeeper]$ sudo docker push 192.168.220.101:30002/bigdata/zookeeper:3.7.0-debian-10-r320
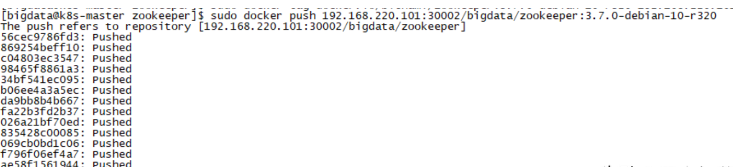
2.4 安装Zookeeper
[bigdata@k8s-master zookeeper]$ helm install zookeeper ./zookeeper -n zookeeper
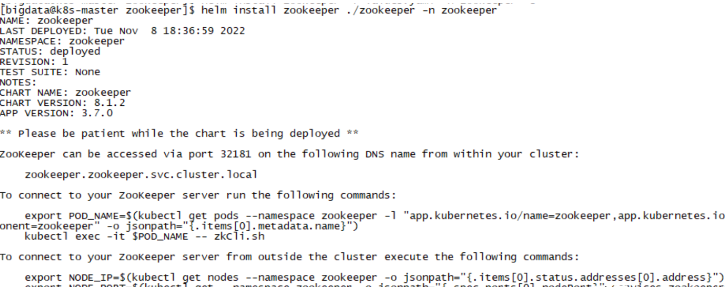
查看 pod 状态
[bigdata@k8s-master zookeeper]$ kubectl get pod -n zookeeper -o wide

2.5 验证zookeeper是否安装成功
[bigdata@k8s-master zookeeper]$ kubectl exec -it zookeeper-0 -n zookeeper -- zkServer.sh status
[bigdata@k8s-master zookeeper]$ kubectl exec -it zookeeper-1 -n zookeeper -- zkServer.sh status
[bigdata@k8s-master zookeeper]$ kubectl exec -it zookeeper-2 -n zookeeper -- zkServer.sh status
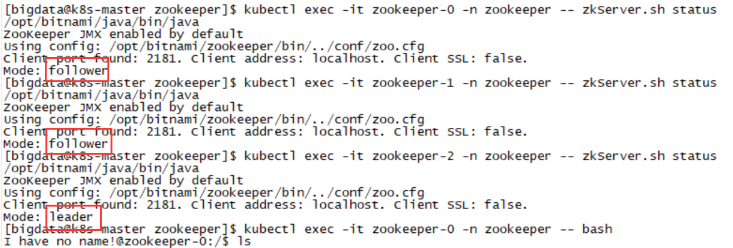
验证zookeeper是否安装成功
三 kafka on k8s 部署
3.1 选择Kafka的仓库地址
如何使用 helm 安装Kafka,helm 必须要知道从哪些仓库可以下载Kafka,有一个非常实用的网站https://artifacthub.io/,可以帮我们选择使用哪个仓库。选择stars数量最多的镜像源 bitnami/Kafka。
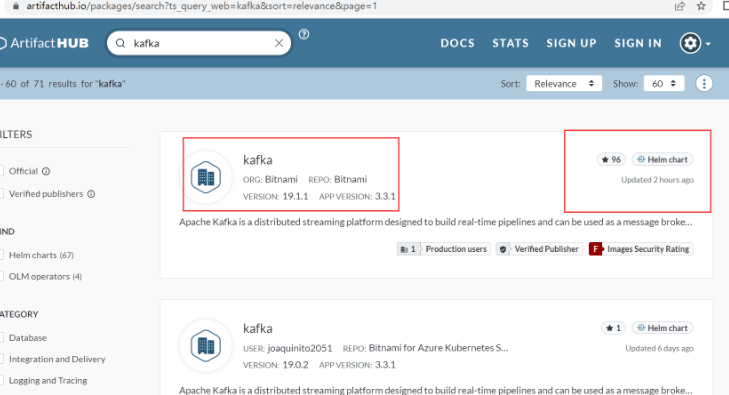
artifacthub.io
既然选好了镜像源,需要将镜像源添加到本地。
3.1.1 添加镜像源
# 添加镜像源
[bigdata@k8s-master zookeeper]$ helm repo add bitnami https://charts.bitnami.com/bitnami
3.1.2 如何选择Kafka版本
在大数据领域,通常都是优先选择稳定的版本,不追求最新版本。可以登录到kafka.apache.org网站上查看,目前kafka3.2.3是最新稳定版本。
可以通过下面的命令,查找Kafka版本,左侧是Chart版本,右侧是Kafka版本;只能根据Chart版本安装Kafka。
[bigdata@k8s-master kafka]$ helm search repo bitnami/kafka -l
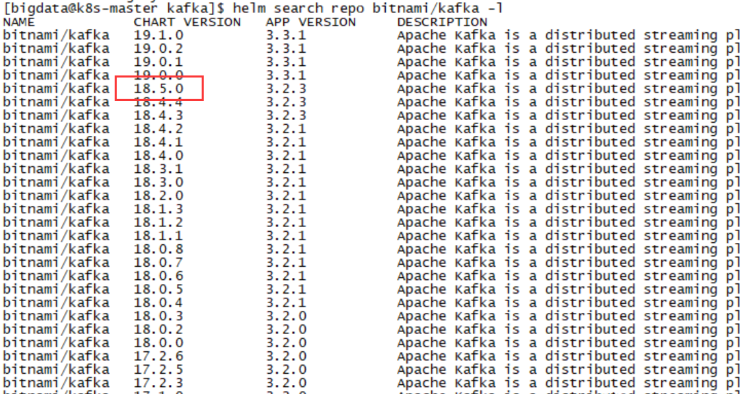
bitnami/kafka
3.1.3 下载Kafka3.2.3
通过查询,发现Kafka3.2.3系列最大的Chart version是18.5.0,因此,我们选择下载version18.5.0
# 下载
[bigdata@k8s-master kafka]$ helm pull bitnami/kafka --version 18.5.0
# 解压
[bigdata@k8s-master kafka]$ tar -zxvf kafka-18.5.0.tgz
3.2 修改配置信息
主要是修改values.yaml文件,values.yaml文件内容比较多,我只列出需要修改的部分。
image:
registry: 192.168.220.102:30002
repository: bigdata/kafka
tag: 3.2.3-debian-11-r1
## 我们的集群只有两个节点,因此kafka的最大副本数只能设置为2
replicaCount: 2
service:
## 将type类型修改为NodePort
type: NodePort
nodePorts:
client: "30092"
external: "30094"
externalAccess:
service:
nodePorts:
- 31001
- 31002
useHostIPs: true
persistence:
storageClass: "kafka-nfs-storage"
zookeeper:
enabled: false
externalZookeeper:
##
servers:
- zookeeper-0.zookeeper-headless.zookeeper
- zookeeper-1.zookeeper-headless.zookeeper
- zookeeper-2.zookeeper-headless.zookeeper
3.3 下载Kafka
每个大公司都有自己的harbor仓库,存储镜像源。我们先pull一份kafka:3.2.3-debian-11-r1镜像,然后push到本地harbor中。
[bigdata@k8s-master kafka]$ sudo docker pull docker.io/bitnami/kafka:3.2.3-debian-11-r1
[bigdata@k8s-master kafka]$ sudo docker tag docker.io/bitnami/kafka:3.2.3-debian-11-r1 192.168.220.102:30002/bigdata/kafka:3.2.3-debian-11-r1
# 上传到本地Harbor
[bigdata@k8s-master kafka]$ sudo docker push 192.168.220.102:30002/bigdata/kafka:3.2.3-debian-11-r1
3.4 安装Kafka
[bigdata@k8s-master kafka]$ helm install kafka ./kafka -n kafka
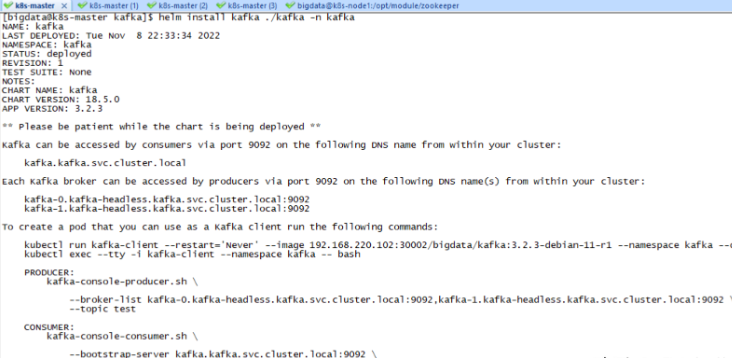
安装Kafka
查看 pod 状态
[bigdata@k8s-master kafka]$ kubectl get pod -n kafka -o wide

查看 pod 状态
3.5 测试验证Kafka
# 切入k8s内部的kafka
[bigdata@k8s-master kafka]$ kubectl exec -it kafka-0 -n kafka -- bash

验证Kafka
# 创建topic
I have no name!@kafka-0:/$ kafka-topics.sh --create --topic demo --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1
Created topic demo.
# 查看topic
I have no name!@kafka-0:/$ kafka-topics.sh --list --bootstrap-server kafka.kafka:9092
demo
# 生产数据
I have no name!@kafka-0:/$ kafka-console-producer.sh --broker-list kafka.kafka:9092 --topic demo
>hello, kafka
>hello, zookeeper
>hello, k8s
>

验证Kafka
# 从最开始处消费数据
[bigdata@k8s-master kafka]$ kubectl exec -it kafka-0 -n kafka -- bash
I have no name!@kafka-0:/$ kafka-console-consumer.sh --bootstrap-server kafka.kafka:9092 --topic demo --from-beginning
hello, kafka
hello, zookeeper
hello, k8s

消费kafka中的数据