
在之前的文章实战教程中,相信大家都感受到 Serverless 的便捷之美,只需上传代码包和镜像就能够轻松上线一个弹性高可用的 Web 应用。但是它仍存在首次启动“冷启动延时”的问题,Mall 应用实例的启动大约 30 秒左右,用户会感受较长时间的冷启动延时,在这个“即时时代”应用程序响应慢多少会有些瑕不掩瑜。(“冷启动”是指函数服务于特定调用请求时的状态,当一段时间没有请求后,Serverless 平台则会回收函数实例;等到下一次再有请求时,系统会再次实时拉起实例,这个过程称之为冷启动。)
在优化冷启动之前,我们先要分析清楚冷启动各个阶段的耗时。首先在函数计算(FC) 控制台的服务配置界面,开启链路追踪功能。
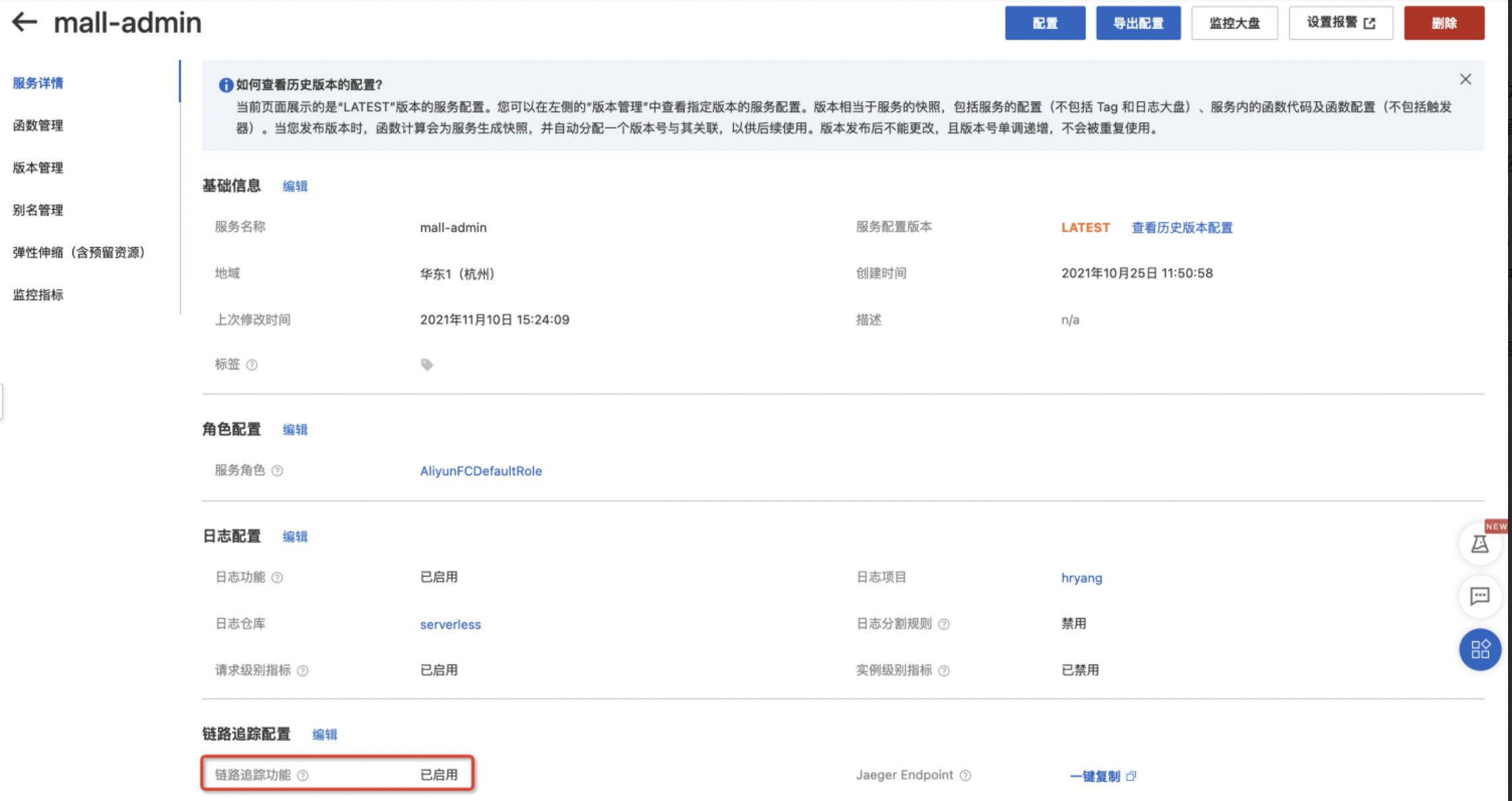
对 mall-admin 服务发起请求,成功后查看 FC 控制台,我们能够看到相应的请求信息。注意关闭“仅查看函数错误”,这样才会显示所有请求。指标监控和调用链路数据收集会存在一定延时,如果没有显示,请等待一会再刷新。找到冷启动标记的请求,点击 “更多” 下的 “请求详情”。
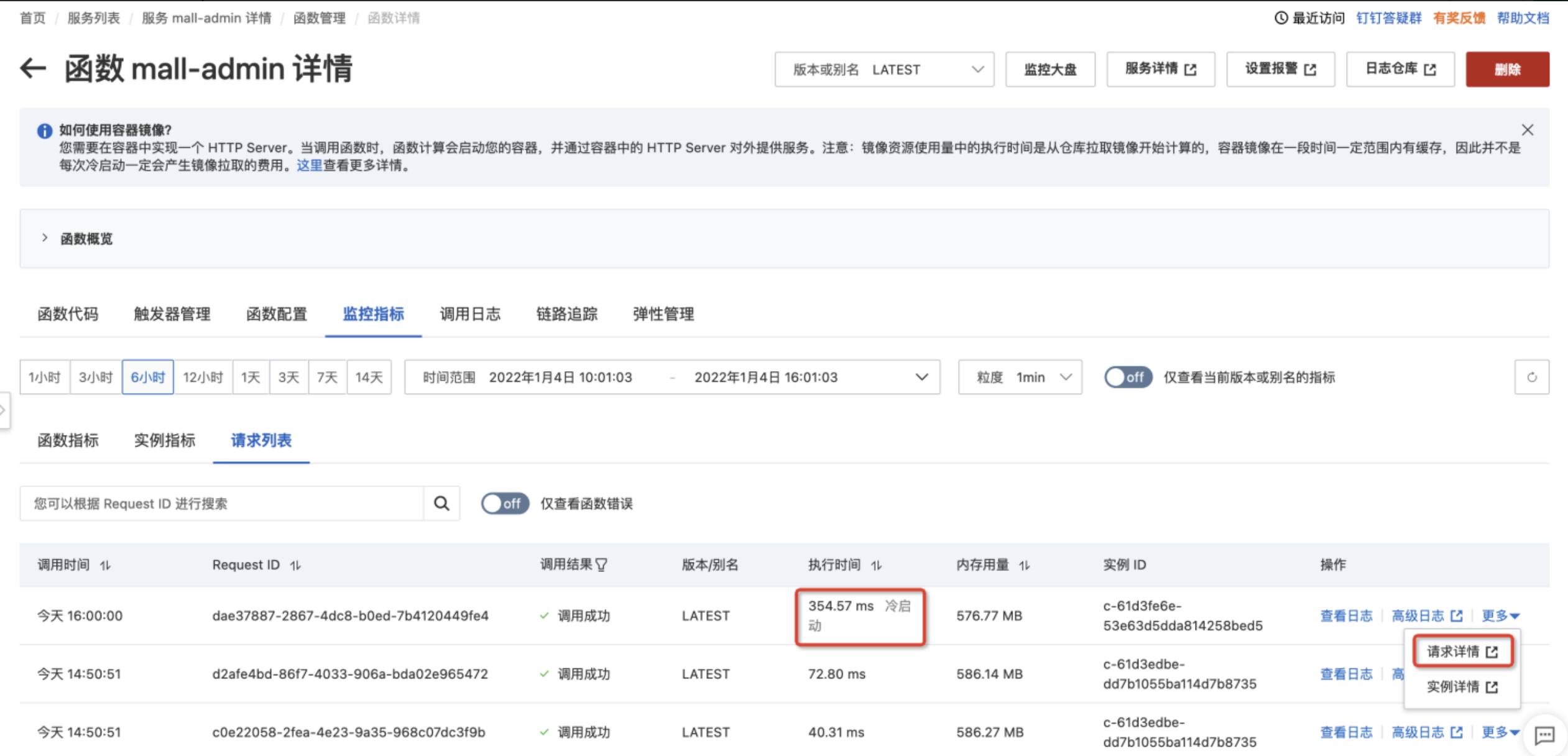
调用链路会显示冷启动各个环节的耗时。冷启动包含以下几个环节:
- 代码准备(PrepareCode):主要是下载代码包或者镜像。由于我们已经启用了镜像加速功能,不需要下载全部的镜像,因此这一步的延时非常短。
- 运行时初始化(RuntimeInitialization):从启动函数开始,到函数计算(FC)系统探测到应用端口就绪为止。这中间包含了应用启动时间。在命令行执行 s mall-admin logs 查看相应的日志时间,我们也能看到 Spring Boot 应用的启动需要花大量的时间。
- 应用初始化(Initialization):函数计算提供了 Initializer 接口,用户可以将一些初始化逻辑放在 initializer 中执行。
- 调用延时(Invocation):处理请求的延时,这个延时非常短。
从上述链路追踪图来看,实例启动时间是瓶颈,我们可以采取多种方式来优化。
1.1. 使用预留实例
Java 类应用普遍启动较慢。应用在初始化时,也需要和很多外部服务交互,耗时较长。这类流程是业务逻辑需要的,很难优化延时。因此函数计算提供了预留实例功能。预留实例的起停由用户自己控制,没有请求也会常驻在那,因此不会有冷启动的问题,当然用户需要为整个实例的运行付费,即便实例没有处理任何请求。
在函数计算控制台,我们可以在“弹性伸缩”页面为函数设置预留实例。
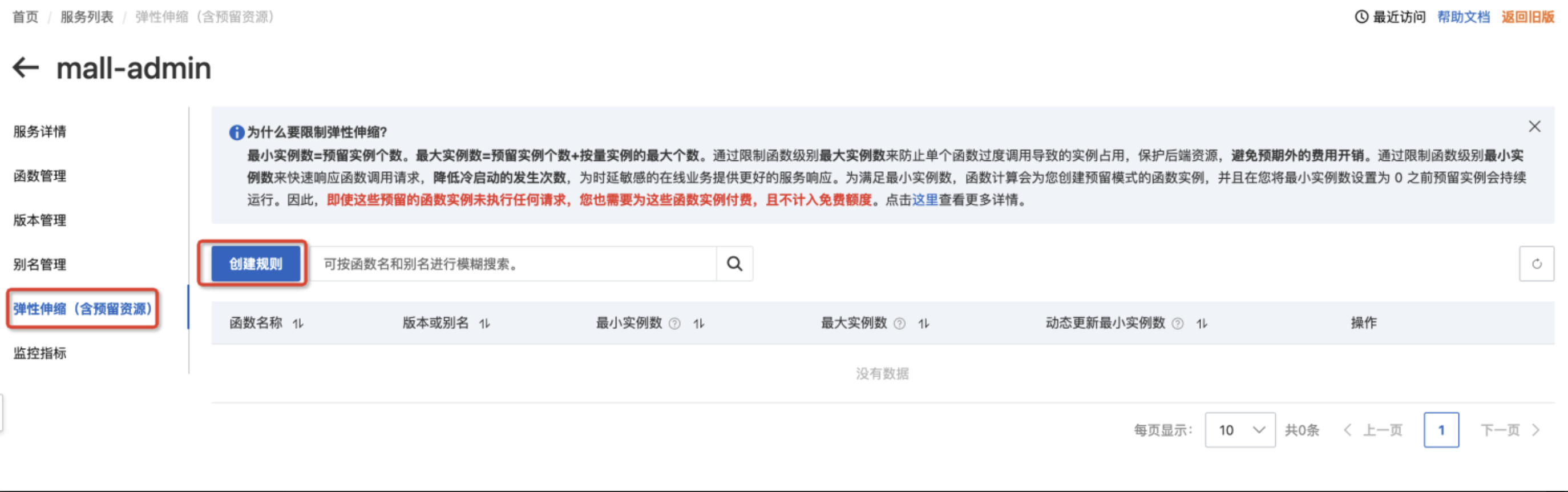
用户在控制台中配置最小和最大实例数。平台会预留最小实例数目的实例,最大实例是指该函数下实例的上限。用户也可以设置定时预留和按指标预留的规则。
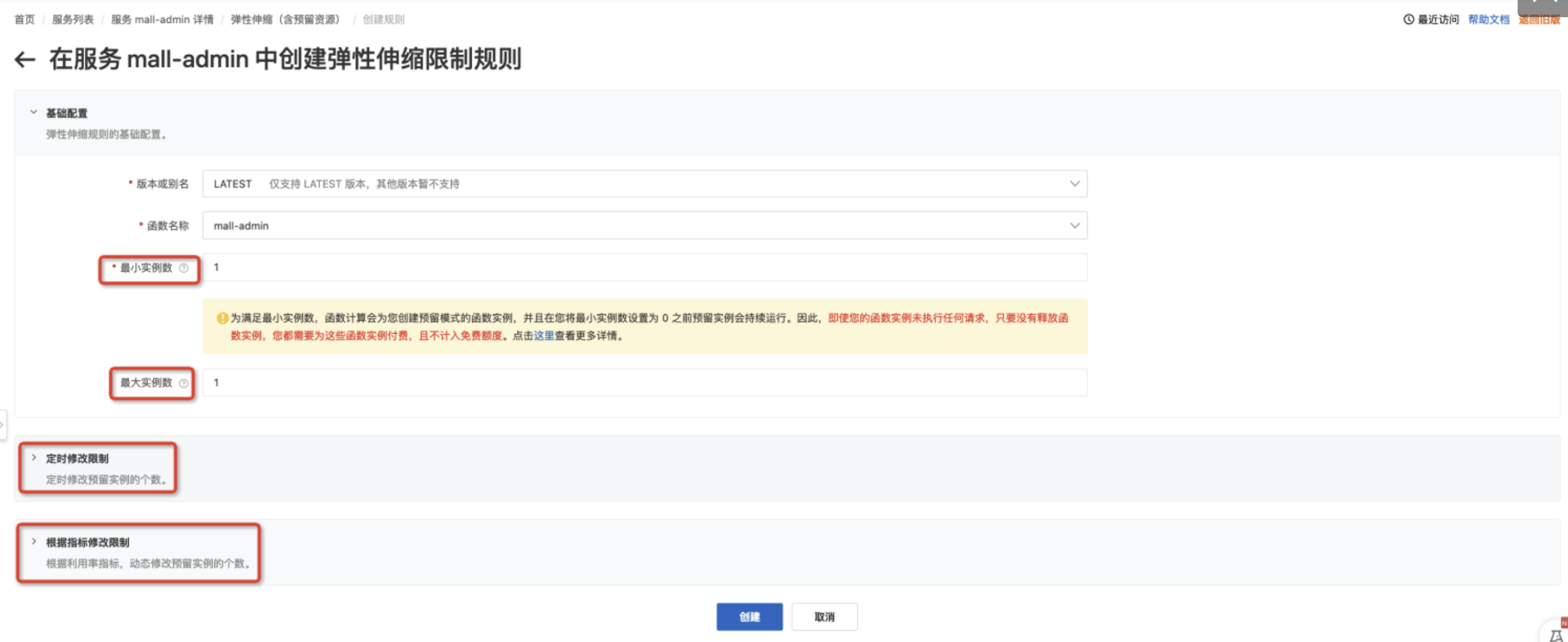
创建预留规则后,系统就会创建预留实例。当预留实例就绪后,我们再访问函数就不会有冷启动。
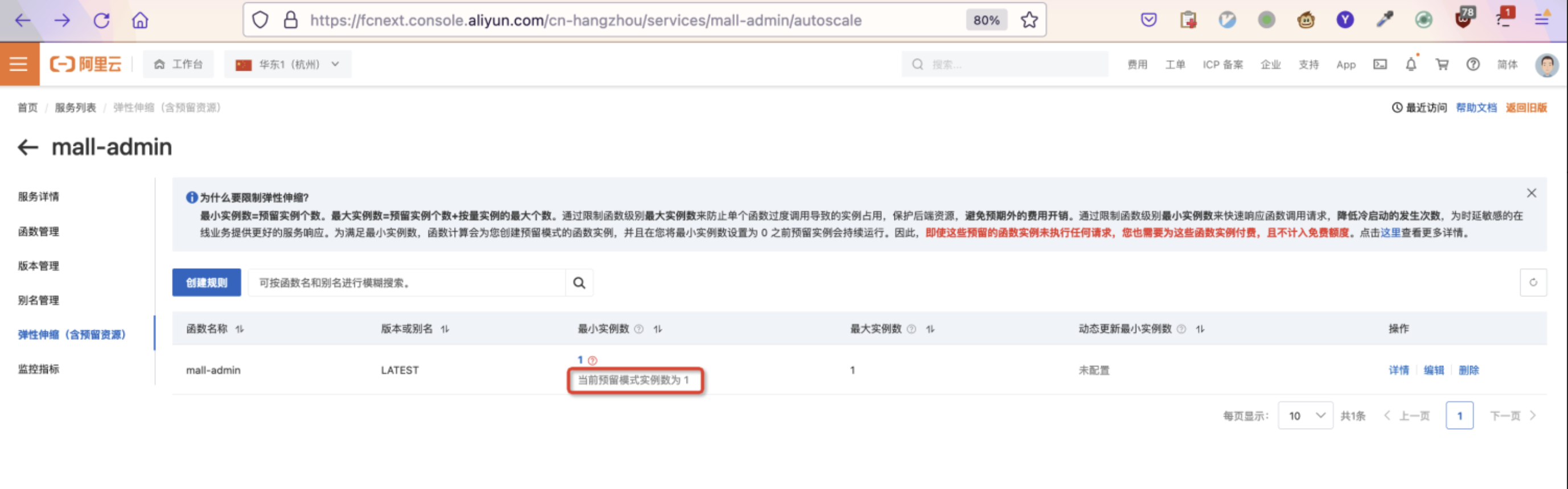
1.2. 优化实例启动速度
延迟初始化
在 Spring Boot 2.2 及更高版本中,可以开启一个全局延迟初始化标志。这将提高启动速度,但代价是第一个请求的延迟时间可能变长,因为需要等待组件首次初始化。
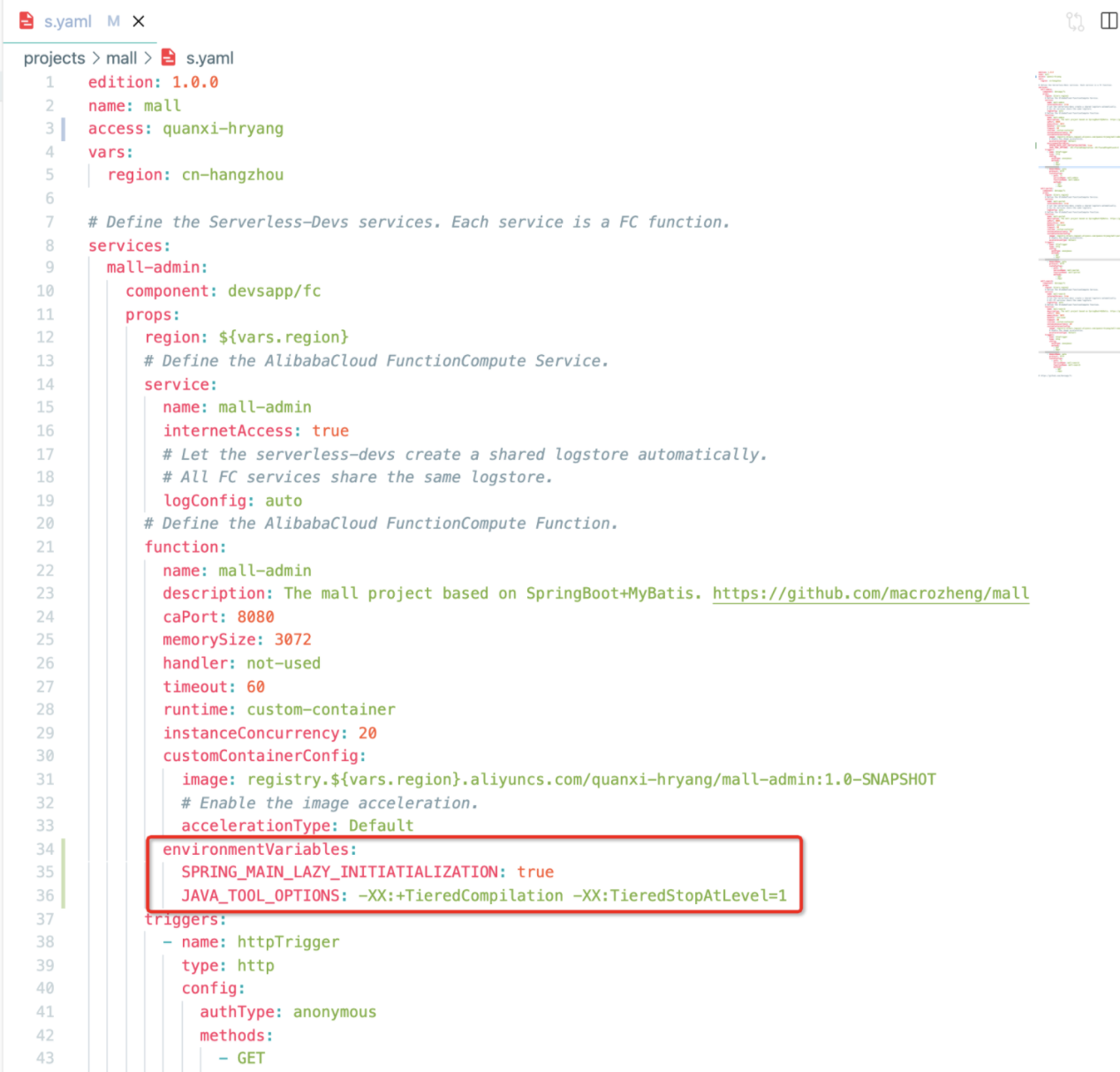
可在 s.yaml 中为相关应用配置以下环境变量
SPRING_MAIN_LAZY_INITIATIALIZATION=true
关闭优化编译器
默认情况下,JVM 有多个阶段的 JIT 编译。虽然这些阶段可以逐渐提高应用的效率,但它们也会增加内存使用的开销,并增加启动时间。对于短期运行的 Serverless 应用,请考虑关闭此优化,以牺牲长期效率换取更短的启动时间。
可在 s.yaml 中为相关应用配置以下环境变量:
JAVA_TOOL_OPTIONS="-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
s.yaml 中设置环境变量示例:
如下图所示,对 mall-admin 函数配置环境变量。然后执行 sudo -E s mall-admin deploy 部署。
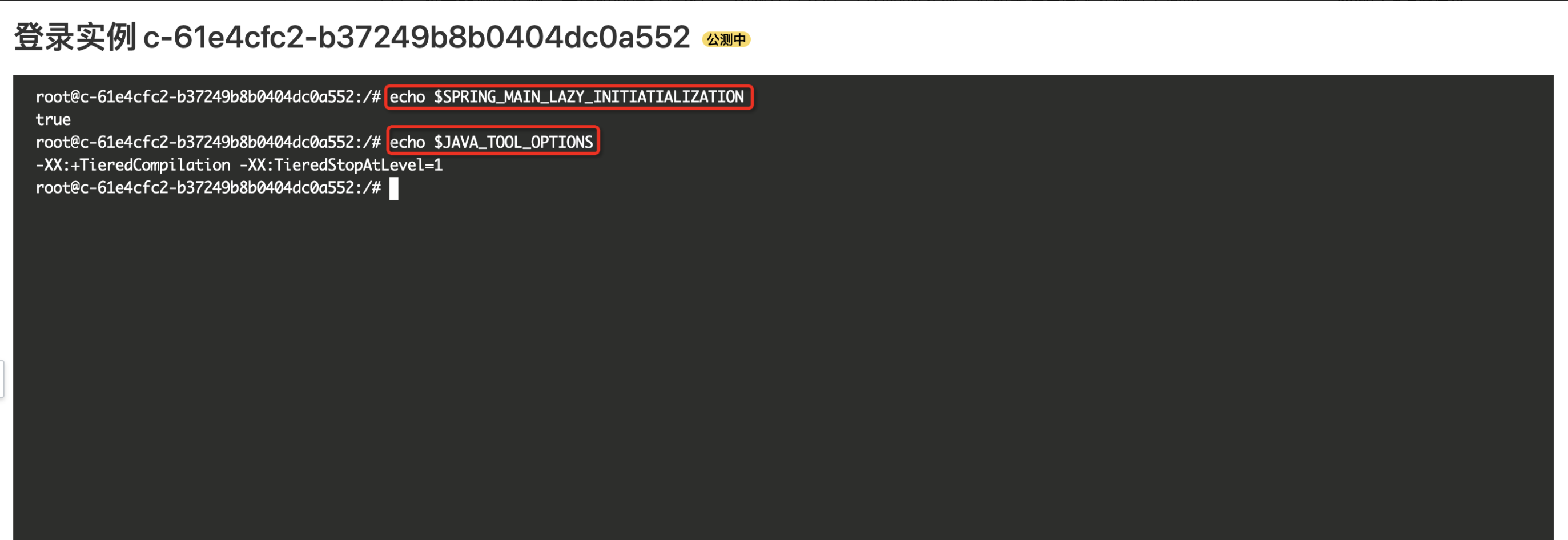
登录实例检查环境变量是否配置正确
在控制台函数详情页的请求列表中找到对应的请求,点击更多中的“实例详情链接”。
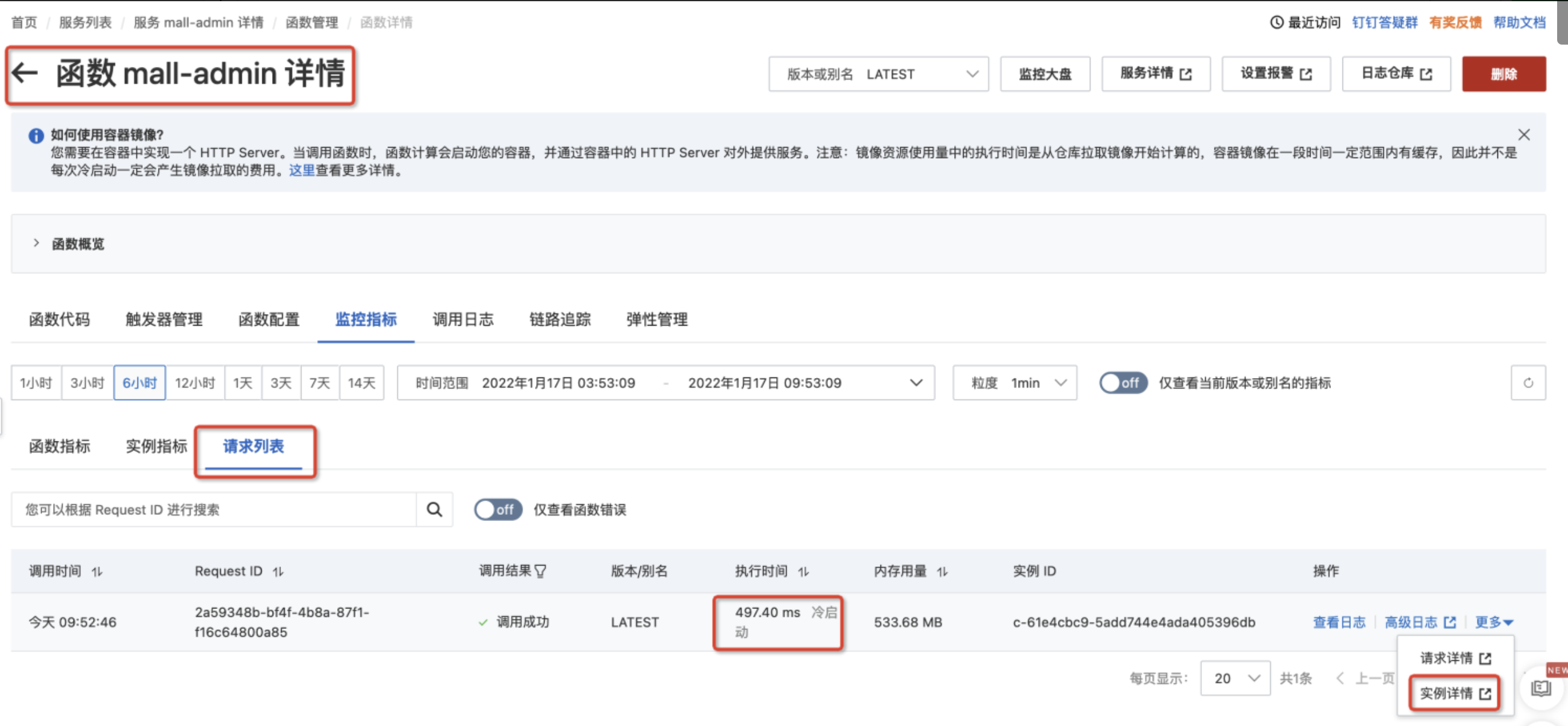
在实例详情页中点击“登录实例”。
在 shell 界面中执行 echo 命令,查看对应的环境变量是否设置正确。
注意:对于非预留实例,一段时间没有请求后,函数计算系统会自动回收实例。此时无法再登入实例(上面的实例详情页面中的登录实例按钮会变灰)。所以请执行调用后,在实例被回收之前尽快登录。
2. 配置合理的实例参数
当我们选择了应用实例规格,比如 2C4G 或者 4C8G,接下来我们希望知道一个实例处理多少请求可以既能充分利用资源又能够保证性能。当处理的请求超过一个限制后,系统能够快速弹出实例,保证应用性能平滑。如何度量实例过载有多个维度,例如 qps 超过一定阈值,或者实例 CPU/Memory/Network/Load 等指标超过阈值等等。函数计算使用实例并发度(Instance Concurrency)来作为实例负载的度量和实例伸缩的依据。实例并发度(Instance Concurrency)是指一个实例能同时执行的请求数。例如将实例并发度设置为 20,则意味着一个实例在任意时刻最大能同时执行 20 个请求。
注意:请区分实例并发度和 QPS 的区别。
使用实例并发度来度量负载有如下优势:
- 系统能够迅速统计实例并发度指标值进行扩缩容。CPU/Memory/Network/Load 等实例级别的指标通常是后台统计,需要花费数十秒的指标统计后才能进行伸缩,难以满足在线应用的弹性伸缩要求。
- 在各种条件下,实例并发度指标都能够稳定的反映系统负载高低。如果以请求延时作为指标,系统难以区分是实例过载导致延时变大,还是下游服务成为瓶颈导致延时变大。例如一个典型的 Web 应用,通常会访问 MySQL 数据库。如果数据库成为瓶颈,请求延时变大,此时扩容不但毫无意义,而且会压垮数据库,让情况更加恶化。QPS 和请求延时相关,也会有上述问题。
实例并发度作为伸缩依据虽然有上述优点,但用户常常并不知道该设置多大的实例并发度。我推荐按照下述流程确定合理的并发度:
- 将应用函数的最大实例数设置为1,确保压测到单个实例的性能。
- 使用负载压测工具对应用进行压测,查看 tps 和请求延时等指标
- 逐步调大实例并发度,如果性能仍然良好,则继续调大;如果性能不符合预期,则调小并发度。