
1 概述
什么是 Scylla?Scylla 官网上面的描述很好的回答了这个问题
The Real-Time Big Data Database
Scale-up performance of 1,000,000s of OPS per node, scale-out to hundreds of nodes and 99% latency of <1 msec
翻译过来是 Scylla 是实时大数据数据库,可以支持每个节点 1,000,000 OPS 的垂直扩展性能,水平可以扩展到数百个节点,99% 的访问延迟可以低于 1 毫秒。Scylla 是性能优异的 NoSQL 宽列存储数据库,完全兼容 Apache Cassandra 并提供了更低的延迟,其 shard-per-core 设计使其能够以亚毫秒平均延迟每秒运行数百万次操作。

压测集群:3 节点 CF=3 CL=1
图片来源于网络
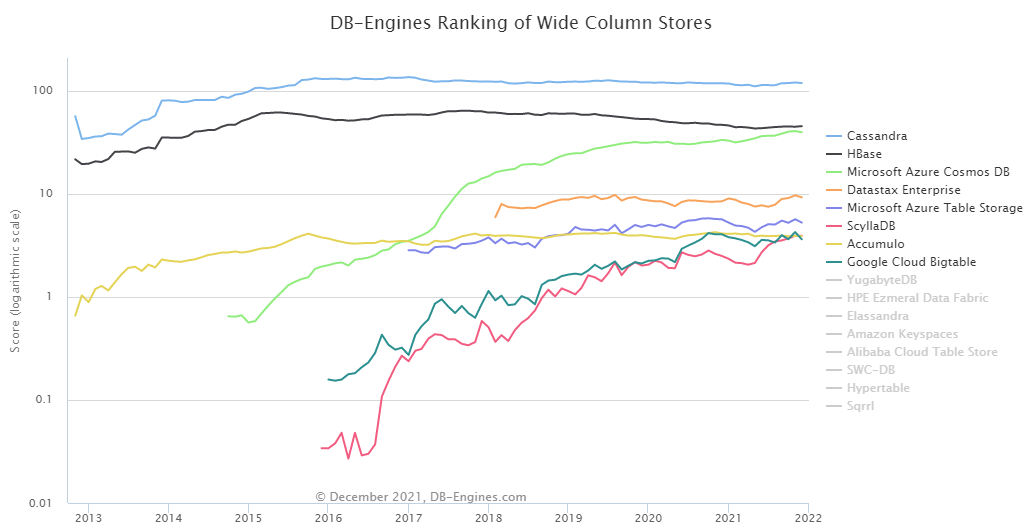
在 DB-Engines 的数据库排名中,Scylla 表现了强大的活力,从 16 年开始排名迅速攀升,目前在宽表数据库领域已经超过了 Bigtable 稳居第六名。
下面我们从几个方面来介绍 Scylla 以及 Scylla 在 OPPO 的应用现状。
2 Scylla 支持的特性
1)完全兼容 Cassandra
Scylla 作为 Apache Cassandra 的替代品和完全支持的 Cassandra 迁移功能的替代品。Scylla 提供相同的 CQL 接口和查询、相同的驱动程序,甚至相同的磁盘 SSTable 格式,但采用了用来消除 Cassandra 性能问题、限制和操作障碍的现代架构。
2)支持可调一致性
Scylla 通过为每个请求指定一个 Consistency Level (CL缩写,一致性级别) 来决定成功写入或读取多少个副本才返回成功。
常用的 Consistency Level 有:
ANY – 写入必须至少写入集群中的一个副本。该等级以最低的一致性提供最高的可用性。
QUORUM – 当大多数副本成功响应后,请求返回成功。如果 RF=3,则需要 2 个副本响应。可以使用公式 (n/2 +1) 计算 QUORUM ,其中n是复制因子。
ONE – 一个副本成功响应后,请求返回成功。跟ANY的区别是ANY写入Hinted Handoff也算写入成功。
LOCAL_ONE – 本地数据中心中至少有一个副本响应。
LOCAL_QUORUM – 本地数据中心的大多数副本做出响应。
EACH_QUORUM – (不支持读取) – 必须写入所有数据中心中的大多数副本。
ALL – 写入必须写入集群中的所有副本,读取等待所有副本的响应。以最高的一致性提供最低的可用性。
无论 Consistency Level 如何设置,写请求总是发送到所有的副本,副本个数由 Replication Factor(RF缩写,复制因子)设置。一致性水平控制在一个客户端什么时候确认操作,而不是实际上有多少个副本被实际更新。在写操作期间,协调器与副本进行通信(副本的数量取决于复制因子)。当指定数量的副本确认写入时,写入成功。
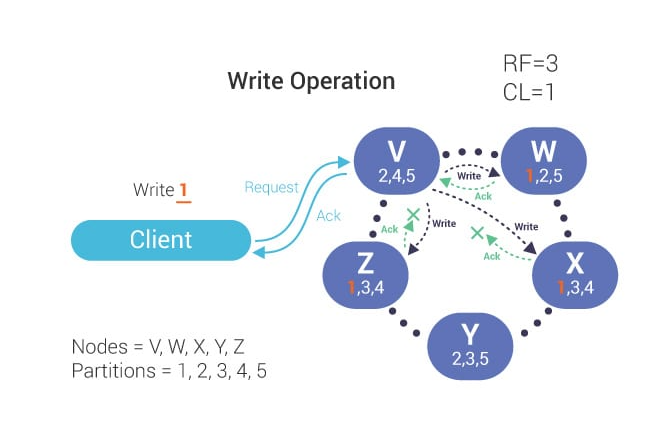
图片来源于网络
在上图中,双箭头表示从客户端进入协调器的写操作请求和返回的确认。由于一致性级别为 1,因此协调器 V 只需要等待写操作发送到集群中的一个节点 W 并获得它的响应。
在读取操作期间,协调器与刚好足够的副本进行通信以保证满足所需的一致性级别。然后将数据返回给客户端。
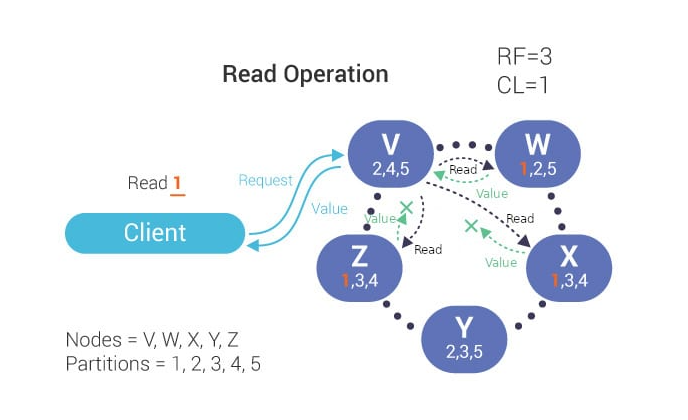
图片来源于网络
Consistency Level 在 CQL 中可根据每个操作进行调整。这称为 tunable consistency(可调一致性)。有时响应延迟更重要,因此有必要在每个查询或操作级别调整设置用来覆盖键空间甚至数据中心范围的一致性设置。换句话说,Consistency Level 设置允许你在一致性与延迟的权衡中选择一个点。
3)高可用
Scylla 是一个高可用的快速 NoSQL 数据库。磁盘驱动器、节点、机架甚至整个数据中心都可能出现故障,你的应用程序不能失败,它们始终在线。这是高可用性数据库系统的目标。Scylla 通过一些机制实现零停机,包括机架和数据中心感知,以及多数据中心复制。
Scylla 集群可以跨越位于任何地理空间的数据中心。Scylla 中的数据以最终一致的方式在数据中心之间自动同步,无需用户创建任何类型的流或批处理来确保集群同步。
4)支持 CQL 事件追踪(CQL Tracing)
Tracing 是一种 Scylla 工具,旨在帮助调试和分析服务器中的内部流程。这种流程的一个例子是 CQL 请求处理。支持概率追踪和慢查询日志。
5)支持物化视图(MV)和全局二级索引(GSI)
物化视图作为 Scylla Open Source 3.0 中的生产就绪功能提供。
在引入物化视图之前,需要通过不同的 key 查找相同的数据,唯一方法是使用非规范化 —— 创建两个完全独立的表并在应用程序中同步它们。但是,以这种方式确保两个或多个视图中数据之间的任何级别的一致性都可能需要重复的代码以及复杂而低效的应用程序逻辑。
Scylla 的物化视图功能将这种复杂性从应用程序移到服务器中。由于到应用程序的往返次数较少,因此这种实现更快、更可靠。使用物化视图,Scylla 自动维护单独表的过程以支持对相同数据的不同查询,并允许使用标准读取路径在每个视图中快速查找数据。
Scylla 在物化视图的基础上实现了全局二级索引。
6)支持 Hinted Handoff
当写入请求发送到 Scylla 节点时,由于节点上的写入负载过重、网络问题甚至硬件故障等原因而无响应时,Scylla 实现了 hinted handoff(提示移交)来确保可用性和一致性。
Scylla 为宕机节点保存了一份写入副本,并在节点重新启动时进行重放。当节点宕机时,写操作流程如下所示:
(1)协调器确定所有的副本节点;
(2)基于复制因子 (RF),协调器尝试写入 RF 节点;
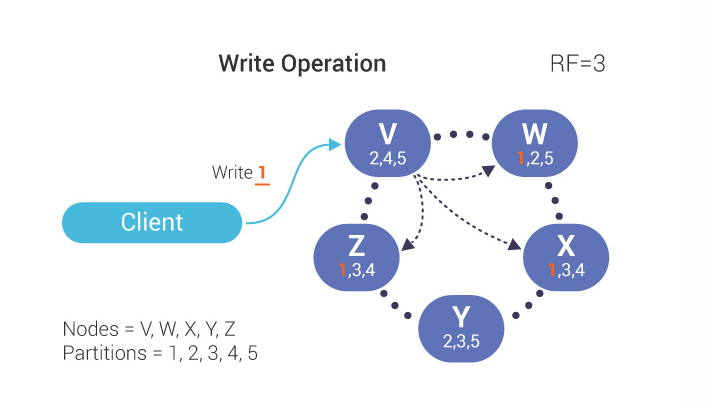
图片来源于网络
(3)如果一个节点宕机,则确认只会从两个节点返回:

图片来源于网络
(4)如果一致性级别不需要来自所有副本的响应,则在这种情况下,协调器 V 将响应客户端写入成功。协调器将为丢失的节点编写并存储提示:
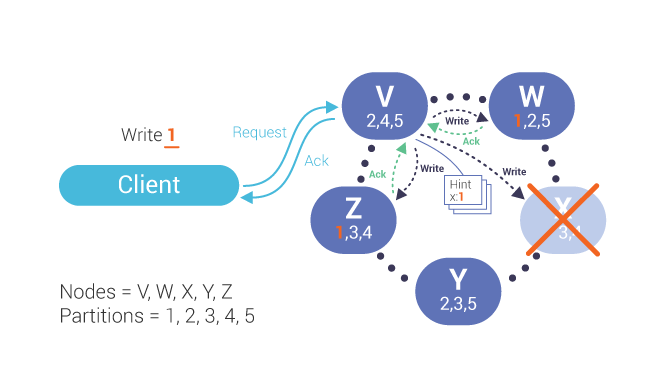
图片来源于网络
(5)一旦宕机节点重新出现,协调器将重放该节点的提示。协调器收到写入确认后,将删除提示。

图片来源于网络
7)轻量级事务(LWT)
4.0 特性。Scylla LWT 使用 Paxos 共识算法提供更强的一致性保证。它们确保分布式数据库上的请求在称为 Compare and Set(比较和设置)的过程中以严格的线性化(串行)方法进行处理。它们也称为 Conditional Updates(条件更新),因为它们可以在提交更新之前测试数据库的现有值。这为单个键提供了原子一致性,允许在全局基础上按顺序执行更新。它们还可用于批处理,以确保在提交批处理更新之前满足所有条件。
8)支持变更数据捕获 (CDC)
你可以通过 CDC 来跟踪对数据库中的基表所做的变更。对基表所做的更改存储在可以由标准 CQL 查询的单独表中。CDC 通过可配置的生存时间 (TTL) 来确保它不会占用过多的磁盘空间。
3 如何引入 Scylla
1)什么样的项目适合使用
-
TB 级别及以上大规模数据存储,在低存储成本的同时需要保证高性能读写
-
对长尾延迟敏感,可以接受最终一致性
-
大量写操作,Scylla 是针对写优化的系统,更适用于写多读少的场景
-
多地分布,Scylla 原生支持多数据中心部署,跨数据中心同步,支持机房级容灾
-
数据可以通过一个 Key 进行分区,该 Key 允许数据库在多个节点上均匀分布
2)什么样的项目不适合使用
-
表有多个访问路径,比如需要许多二级索引。
-
应用程序依赖于具有顺序值的行,比如 MySQL 自动增量。
-
需要支持 ACID,对一致性敏感。
-
需要支持连接和聚合,Scylla 支持聚合函数,不过会对性能有损耗。
-
Scylla 不支持锁,不支持开始/提交事务的语法。
-
Scylla 更新和删除都是作为写入的特殊情况来实现的,不支持原子更新(部分场景也可以使用 LWT,但是对性能有损耗)。
4 Scylla 在 OPPO 的使用现状
1)项目背景
OPPO 业务使用了大量的 Redis 集群作为业务层缓存,业务部门对 Redis 协议十分了解。所以当 OPPO 在做自研持久型 KV 存储 Parker 时,很自然选择了 Redis 协议。随着越来越多业务的接入,Redis 协议越来越难以支持业务的需求。当时推荐团体在寻求一个存储系统,期望有以下功能:
-
TB 级别数据量
-
写多读少,读 P99 低于 5ms
-
支持元素聚合运算
-
支持子 Key 级别过期(区别于 Redis 的 Key 级别过期)
-
支持跨机房容灾
如果在 Parker 的基础上新开发功能支持业务需求,有以下几个风险
-
从 0 到 1 开发,工作量大且风险高,无法满足业务快速上线的需求
-
需要扩展 Redis 协议支持新功能,而 Redis 协议本来只是为内存型 KV 存储设计的,在上面做过度的修改会遇到很多限制
2)为什么选择 Scylla
在前期预研阶段,我们放弃了改造 Redis 协议,并通过接口支持、成熟度、可维护性、使用语言、性能多方面对比,最终选择了 Scylla。选择 Scylla 可以带来几个好处
-
显著的存储成本下降,业务侧提供的数据显示,使用 Scylla 存储成本可以下降到原来的 70%以上。不过该数据会根据业务形态的不同有所变化。
-
稳定的 P99 延迟。目前 Scylla 主要用于推荐的算法特征,具有写入量大读取请求量小的特点,在使用 Scylla 前如何在数据大量写入时业务的读取仍能保证稳定的低延迟是个难题。
-
简单的运维。Scylla 大部分运维场景都有相应的文档并提供了 nodetool 来管理集群,只需要根据运维文档的步骤执行即可,大部分运维操作对业务请求影响极小;Scylla 不依赖外部组件,采用 p2p 架构设计,没有单点问题,大大减少了部署和维护的成本;Scylla 对外只提供了少量的配置,大部分存储相关的参数会根据业务数据动态调整,大大减少了传统 LSM 型数据库调参的成本。
3)Scylla 宽表存储平台建设
Scylla 提供了集群管理端程序,但是开源版本并没有支持全部的功能,并且限制了集群的规模。OPPO 自己重新实现了 Scylla 管控台,支持:
-
集群快速申请
-
节点上下线
-
集群扩缩容
-
机房扩缩容
-
慢查询日志
-
数据备份还原
-
集群销毁
-
定时 Repair
-
集群监控与告警
目前已经可以通过管控台对Scylla集群进行运维管理,并在慢查询日志和监控的帮助下协助业务定位不合理的使用,帮助业务更好地使用 Scylla。目前在 OPPO Scylla 的运维仍属于前期摸索的阶段,期待后续能有更多的业务接入,为公司创造更高的价值。
4)Scylla 最佳实践
在 Scylla 产品化过程中遇到了一些问题,给大家分享一下
-
Scylla 对内存磁盘有一些要求,建议内存每个 lcore 16 GB 或 2GB(以较高者为准),磁盘建议使用本地盘 SSD,与内存的比例为 30 : 1。
-
Scylla 会尽可能地多地使用内存和 CPU 来提供更高的性能,需要使用 Scylla 提供的监控指标来判断 Scylla 是否处于高负载。
-
Scylla 不支持服务端限速,如果写入过快会导致读请求延迟增大,遇到这种情况需要业务自行限速或者对集群进行扩容。
-
如果写入速度快于集群处理速度会触发 Scylla 限流机制导致写请求延迟增大,异地多机房同步会加剧这种限流的发生。
-
SizeTieredCompactionStrategy 与 LeveledCompactionStrategy 进行对比,LeveledCompactionStrategy 读性能远高于 SizeTieredCompactionStrategy,但是如果有数据写入读延迟更容易受到影响,如果写入比较频繁,建议使用 SizeTieredCompactionStrategy
-
同一个 partition key 下的数据尽可能通过 batch 一次性批量写入
5)Scylla 在业务的落地
目前Scylla在OPPO主要用于存储推荐系统的算法特征,作为redis hash的低成本替代品。后续会从推荐、IoT、安全等维度持续推进Scylla的落地,敬请期待。
5 总结
Scylla 优异的性能表现主要依赖其抽象出来的异步 IO 框架 Seastar,这方面网络上已经有很多文章进行了较为全面的介绍,本文不再赘述,感兴趣的可以自行去了解。Scylla 的 Shared-nothing 设计和根据业务负载自动调整的特性令人印象深刻,期待越来越多的人可以加入到 Scylla 的探索中。
6 引用
https://www.Scylla.com/product/release-notes/
https://db-engines.com/en/ranking/wide+column+store/all
https://www.Scylla.com/product/technology/
https://www.Scylla.com/scylla-vs-cassandra/
https://university.Scylla.com/courses/scylla-essentials-overview/lessons/high-availability/topic/consistency-level/
https://www.Scylla.com/glossary/high-availability-database/
https://docs.Scylla.com/architecture/anti-entropy/hinted-handoff/
https://www.Scylla.com/open-source-nosql-database/4-x/
https://www.Scylla.com/open-source-nosql-database/3-x/
https://blog.pythian.com/cassandra-use-cases/
https://docs.scylladb.com/getting-started/system-requirements/
https://mp.weixin.qq.com/s/IXQE-hVIqOghkFsjvuiFNg