
1. 选择索引的几个因素
前面我们学习了一条SQL语句的查询和更新过程,知道了大概的流程为:连接器->分析器->优化器->执行器;
其中索引的选择就是在优化器那一步,因为选择一个好的索引就会对语句的优化起到关键的作用;
优化器选择索引,会考虑如下几个因素:
扫描的行数:
这里的扫描行数不是真实的扫描行数,而是一个预估值;
这个预估的扫描行数是根据索引的区分度来统计得出的;
索引的区分度简单点来理解,就是一个表中的索引的不同值的个数,不同值越多,区分度越好(具体的统计细节下面会有介绍),
是否使用临时表:
临时表顾名思义就是临时使用的表,在会话完成后就会结束;
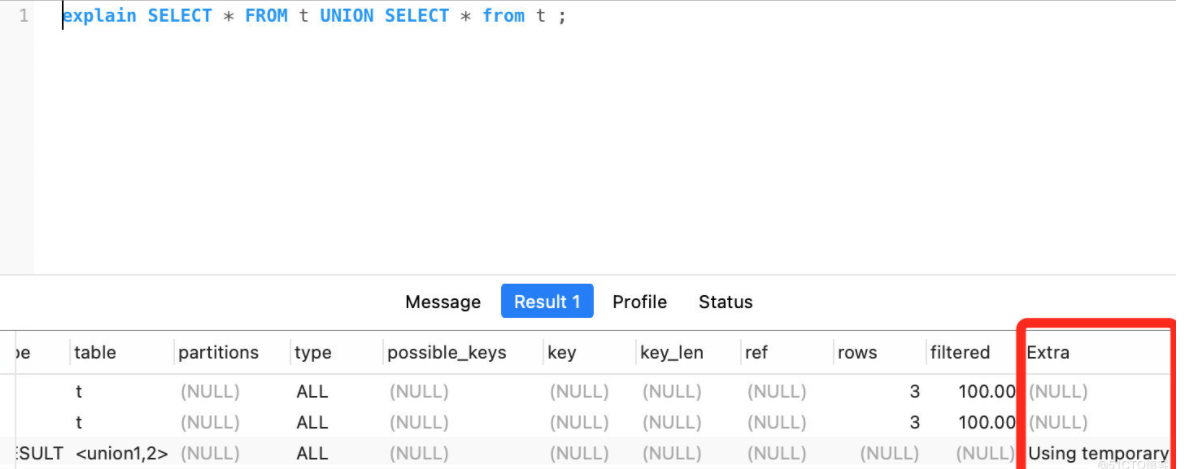
比如我们在使用union联合查询并集时,就会用到临时表,如下所示:可以看到 extra这一列显示为Using temporary就是用了临时表才存储查询结果;
是否需要排序:如果索引A需要排序,而索引B不需要排序,那么系统会优先考虑不需要排序的索引;
你可能会有疑问,索引不都是有序的吗?怎么会需要排序呢
这里排序的场景是:当筛选条件中有多个索引的情况下,且需要 order by 的场景,比如下面的语句:假设有10万条数据,a和b都是索引
explain select * from t where (a between 1 and 10000) and (b between 10000 and 50000) order by b limit 1;
此时按扫描行数来看的话,应该是选择索引a,因为索引a只需要扫描1000行,而索引b需要扫描50000行;
但是实际上系统选择的索引是b,通过执行explain可以看到,如下所示:

这是因为如果用了索引a来查询数据,那么查询到的结果集还要根据b字段进行排序;
在这里,系统自觉地认为排序会影响查询的性能,且影响要大于多扫描的5万行数据,所以就选择了索引b;
这里我们可以试着把order by b 去掉,此时系统就会选择索引a;
还有其他的一些因素,比如是否需要回表等等;
2. 索引的区分度
索引的区分度:指的是索引上不同值的个数,也称为"基数"(cardinality);
当一个索引上,不同值的个数越多,基数就越大,这个索引的区分度越好;
通过如下的命令可以查看索引的区分度:
show index from t

系统是怎么取得这个基数值的呢?
首先可以肯定的是,基数值不是通过逐行扫描比对获取的,因为这样的话效率就太低了;
实际上系统的方法还是比较粗暴的,它是通过采样统计的方法来获取;
下面我们就介绍下采样统计;
3. 索引的采样统计
为啥要用采样统计呢?
就是上面我们介绍的,如果全表扫描的话效率很低,所以通过这种简单直接的方式,会提高效率,当然会损失一些精度;
那采样统计的流程是怎么样的呢?
首先系统会去取出N个数据页来做采样统计;这里的N是有默认值的,下面会介绍;
然后再统计每个数据页上不同值的个数,再做平均得到一个平均基数值 Avg;此时我们有了每个数据页上的基数值Avg;
最后再用Avg*数据页的数量,就是整个表的基数值。
采样统计的时机是什么时候?
在更新数据时,如果更新的记录数比例超过 1/M,就会重新执行一次采样统计(M有默认值,下面介绍);
怎么存储采样统计的结果?
通过设置 innodb_stats_persistent 的值来选对应的存储方式:
on 统计信息会持久化存储,默认的N=20,M=10
off 统计信息只会存在内存中,默认的N=8,M=16
如果采样统计偏差太大怎么办?
比如我们用explain命令查看的预估扫描行数为10000,但实际上通过show index 命令查看的基数值为20000多(可能由于多个会话同时更新数据导致);
这是我们就可以手动修正,命令如下:
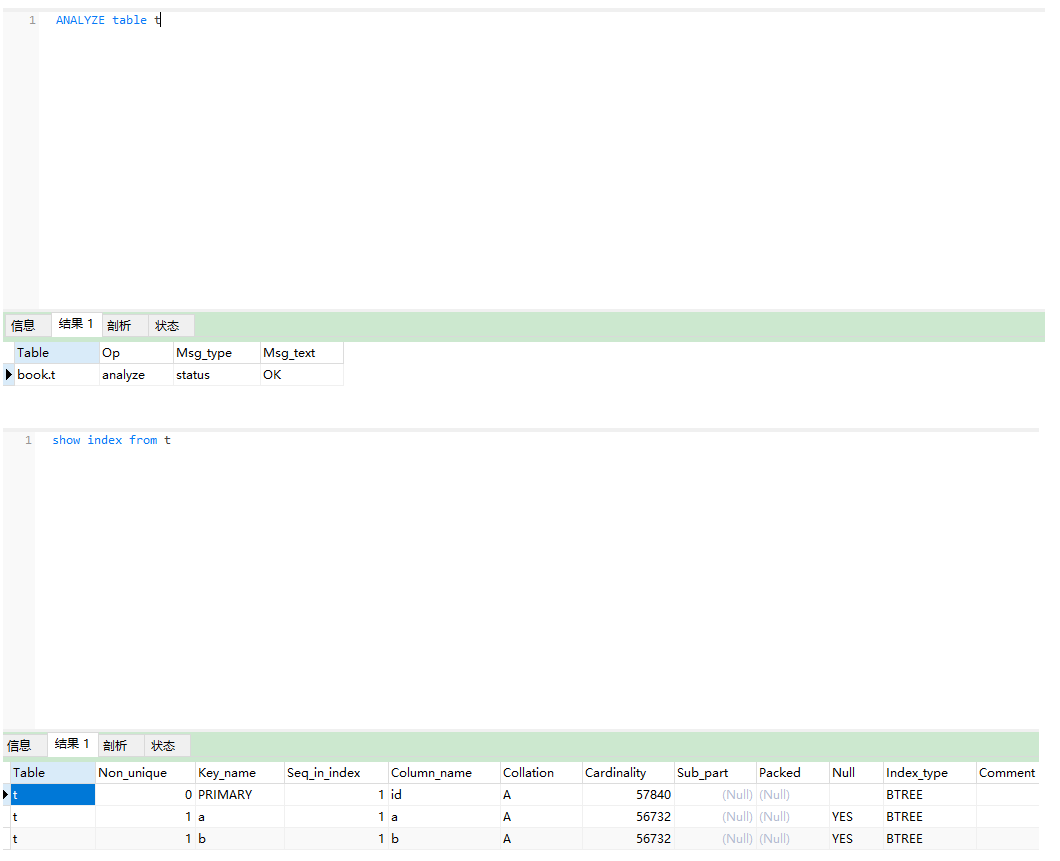
analyze table t;
1.
修正后,再次执行show index 就可以看到跟预估的扫描行数差不多了
4. 选错索引的解决办法
选错索引有多种情况,比如上面分析的预估扫描行数出错,需要排序等等,都会导致系统使用错误的索引;
当然办法总比困难多,下面就简单介绍下对应的解决办法;
预估扫描行数跟实际的差太多?
可以通过analyze table t来进行修正;
比如下面的例子,我本来只有2万多数据,用show index分析也是显示基数值为2万多;

但是当我把数据增加到5万多时,再次用show index分析还是显示2万多;
这时就可以执行analyze table t命令来修正,修正后如下所示,显示为5万多,正常了;
- 排序导致的索引选错:
解铃还须系铃人,既然排序导致的选错索引,那么我们可以修改排序;
比如下面的例子:
select * from t where (a between 1 and 10000) and (b between 10000 and 50000) order by b limit 1;
这里系统选择索引b的原因上面有介绍,就是系统认为索引b虽然扫描行数多,但是可以减少排序带来的性能消耗,所以系统选了索引b;
**那么我们可以将order by b改为order by b,a,**这样一来,索引b和索引a都需要排序,那么排序就不在性能考虑范围之内了,剩下的考虑因素就是扫描行数,此时系统就会选择索引a了;
不过这种改法会修改原有的语义,比如上面的例子只是返回一个数据limit 1;所以将order by b改为order by b,a都是返回结果集中b最小的那一个;
但是如果没有limit限制,那么改了之后返回的结果集顺序就不一致了;
还有一个办法就是删除索引b,前提是确保其他地方没有用到索引b;
通用的解决办法:
上面两种是针对特定的场景而言,其实有一个通用的办法就是强制系统选择某个索引,命令为:
force index (a)
不过这种办法缺点也很明显,就是不够敏捷,比如发现问题、修改索引、测试上线整个过程会比较耗时;