
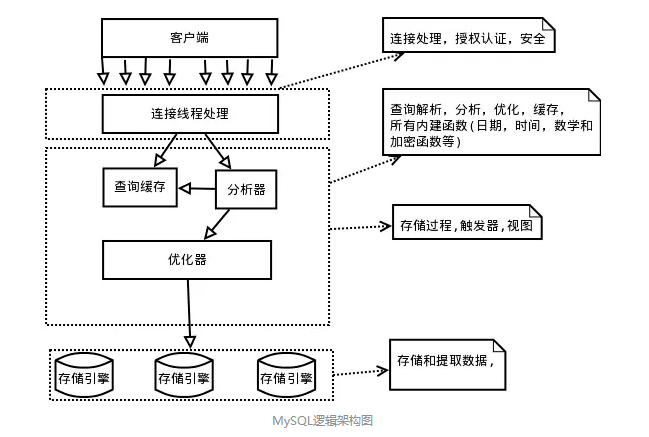
- 第一层为客户端的连接认证,C/S都有此架构
- 第二层为服务器层,包含MySQL的大多数核心服务功能
- 第三层包含了存储引擎,服务器通过API与其通信,API规避了不同存储引擎的差异,不同存储引擎也不会互相通信,另外存储引擎不会去解析SQL(InnoDB是例外,它会解析外键定义,因为服务器本身没有实现该功能)
1.1 连接管理及安全性
- 每个客户端在服务器进程中拥有一个线程
-
服务器会负责缓存线程,不需要为每一个新建的连接创建或销毁线程(5.5以后版本提供了线程池,可使用少量线程来服务大量连接)
-
服务器基于用户名、原始主机信息和密码对客户端进行认证,连接成功后会验证某个特定操作的权限。
1.2 优化和执行
- MySQL会解析查询,创建内部数据结构(解析树),并对其进行各种优化(重写查询、决定表的读取顺序、选择适合的索引)
- 用户可以通过特殊的关键字提示(hint)优化器,影响MySQL的决策过程。也可以请求优化器解释(explain)优化过程的各个因素,便于用户重构查询和schema,修改相关配置
- 优化器不关心表使用的存储引擎,但是存储引擎对优化查询有影响。优化器会请求存储引擎提供容量或某个具体操作的开销信息,已经表数据的统计信息等。
- 对于SELECT语句,在解析查询前,服务器会先检查查询缓存(Query Cache)。
2. 并发控制
两个层面的并发控制: 服务器层和存储引擎层
2.1 读写锁
- 共享锁(shared lock), 读锁(read lock):共享,相互不阻塞
- 排他锁(exclusive lock), 写锁(write lock):排他(会阻塞其它的读写锁)
2.2 锁粒度
- 一种提供共享资源的并发性:让锁定对象更有选择性。尽量只锁定需要修改的部分数据\数据片,锁定的数据量越少,并发程度越高。
- 锁的各种操作(获得锁,检查锁是否解除,释放锁)需要消耗资源。
- 锁策略:
- 表锁(table lock):
- 最基本、开销最小的策略。服务器层实现
- 锁定整张表。写锁阻塞其它锁,读锁互不阻塞。
- 特定场景下,表锁也可能有良好的性能。如READ LOCAL表锁支持某些类型的并发写操作。写锁比读锁有更高优先级,可能会被插入到读锁队列的前面。
- 存储引擎可以管理自己的锁,服务器层还是会使用各种有效的表锁去实现不同的目的。如,服务器会为ALTER TABLE等语句使用表锁,而忽略存储引擎的锁机制。
- 行级锁(row lock):
- 最大程度地支持并发处理,也带来了最大的锁开销。
- 只在存储引擎实现(InnnoDB和XtraDB等)
- 表锁(table lock):
3. 事务
- 事务是一组原子性的SQL查询,或者说一个独立的工作单元。
- 事务的ACID:
- 原子性(atomicty):一个不可分割的最小工作单元。
- 一致性(consistency):数据库总是从一个一致性状态转换到另一个一致性的状态。
- 隔离性(isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- 持久性(durability):事务提交后,其所做的修改会永久保存到数据库中。(没有100%的持久性持久性保证策略)