深度学习在推荐系统中的应用最早可以追溯到2007年Hinton跟他的学生们发表的一篇将受限玻尔兹曼机应用于推荐系统的文章(Explainable Restricted Boltzmann Machines for Collaborative Filtering),随着深度学习在计算机视觉、语音识别与自然语音处理的成功,越来越多的研究者及工业界人士开始将深度学习应用于推荐业务中,最有代表性的是2016年Google发表的wide & deep模型和YouTube深度学习推荐模型(这两个模型我们下面会重点讲解),这之后深度学习在推荐上的应用如雨后春笋,使用各种深度学习算法应用于各类产品形态上。本节我们选择几个有代表性的工业级深度学习推荐系统,讲解它们的算法原理和核心亮点。
YouTube深度学习推荐系统
该模型发表于2016年,应用于YouTube上的视频推荐。按照工业级推荐系统的架构将整个推荐流程分为两个阶段:候选集生成(召回)和候选集排序(排序)(见下图),这两个阶段本质上就是两个大的过滤器。构建YouTube视频推荐系统会面临三大问题:规模大(YouTube有海量的用户和视频),视频更新频繁(每秒钟都有数小时时长的视频上传到YouTube平台,噪音(视频metadata不全、不规范,也无法很好度量用户对视频的兴趣),通过将推荐流程分解为这两步,并且这两部都采用深度学习模型来建模,很好地解决了这三大问题,最终获得非常好的线上效果。
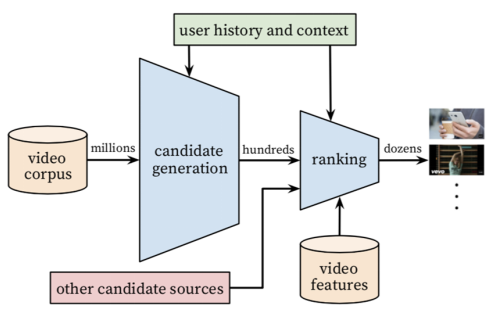
YouTube深度学习推荐系统架构
候选集生成阶段根据用户在YouTube上的行为和场景特征为用户生成几百个候选视频,比如说基于用户的观看历史、观看时长和相似用户的浏览记录(相似用户是通过视屏ID、搜索关键词及相关用户统计信息来决定的),候选集视频期望尽量匹配用户可能的兴趣偏好。排序阶段从更多的(描述视频和用户丰富的特征)维度,通过目标期望函数给每个视频设定分数,根据分数的排名,将用户最有可能点击的几十个作为最终的推荐结果。排序阶段主要依据用户浏览记录、搜索记录、视频观看人数和视频新鲜度等进行筛选。
划分为两阶段的好处是可以更好地从海量视频库中为用户找到几十个用户可能感兴趣的视频(通过两阶段逐步缩小查找范围),同时可以很好地融合多种召回策略召回视频。下面我们分别来讲解这两个步骤的算法。
1. 候选集生成
通过将推荐问题看成一个多分类问题(类别的数量等于视频个数),基于用户过去观看记录预测用户下一个要观看的视频的类别。利用深度学习(MLP)来进行建模,将用户和视频嵌入同一个低维空间,通过softmax激活函数来预测用户在时间点t观看视频i的的概率。具体预测概率公式如下:
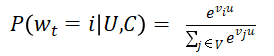
公式中的u、v分别是用户和视频的嵌入向量,u是由“用户特征”与“上下文特征”拼接得到的特征向量,用户历史上看过的视频的向量也是u的组成部分。。U是用户集,C是上下文。Vi代表第i个视频的向量,是需要优化的变量,通过训练才得到。这是一个标准的softmax公式,表示用户U在上下文C的情况下,观看第i个视频的概率。该方法通过一个(深度学习)模型来一次性学习出用户和视频的嵌入向量。
由于用户在YouTube的显示反馈较少,该模型采用隐式反馈数据,这样可以用于模型训练数据量会大很多,这刚好适合深度学习这种强依赖数据量的算法系统。
为了更快地训练深度学习多分类问题,该模型采用了负采样机制(重要性加权的候选视频集抽样)提升训练速度。最终通过最小化交叉熵损失函数(cross-entropy loss)求得模型参数。通过负采样可以将整个模型训练加速上百倍。
候选集生成阶段的深度学习模型结构如下图。首先将用户的行为记录按照word2vec的思路嵌入到低维空间中,将用户的所有点击过的视频的嵌入向量求平均(如element-wise average),获得用户播放行为的综合嵌入表示(即下图的watch vector)。同样的道理,可以将用户的搜索词做嵌入,获得用户综合的搜素行为嵌入向量(即下图的search vector)。同时跟用户的其他非视频播放特征(地理位置、性别等)拼接为最终灌入深度学习模型的输入向量,再通过三层全连接的ReLU层,最上一层ReLU层可以认为是一个嵌入表示,表示的是用户的嵌入向量,那么怎么获得视频的嵌入向量呢?是通过用户嵌入向量经过softmax变换获得,这样用户和视频的嵌入都确定了。最终可以通过用户嵌入在所有视频嵌入向量空间中,按照内积度量找最相似的topN作为候选集。通过这里的描述,我们可以将候选集生成阶段看成是一个嵌入方法,是矩阵分解算法的非线性(MLP多层感知机)推广。
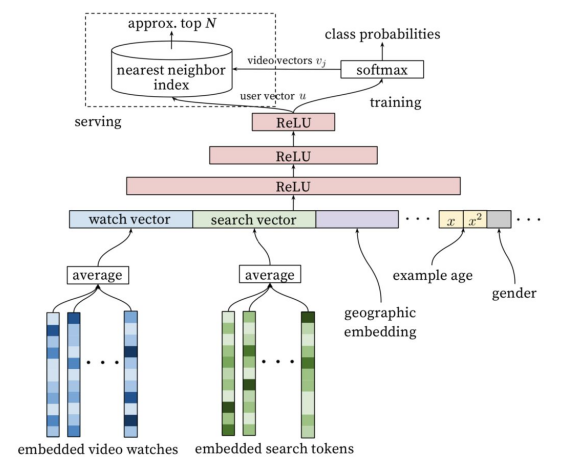
候选集生成阶段深度学习模型结构图
候选集生成阶段的亮点除了创造性地构建深度学习多分类问题、通过用户、视频的嵌入获取嵌入表示,通过KNN获得候选集外,还有很多工程实践上的哲学,这里简单列举几个:
(1) 每个用户生成固定数量的训练样本,“公平”对待每一个用户,而不是根据用户观看视频频度的多少按照比例获取训练样本(即观看多的活跃用户取更多的训练样本),这样可以提升模型泛化能力,从而获得更好的在线评估指标。
(2) 选择输入样本和label时,是需要label观看时间上在输入样本之后的,这是因为用户观看视频是有一定序关系的,比如一个系列视频,用户看了第一季后,很可能看第二季。因此,模型预测用户下一个要看的视频比预测随机一个更好,能够更好地提升在线评估指标,这就是要选择label的时间在输入样本之后的原因。
(3) 模型将“example age”整合到深度学习模型的输入特征中,这个特征可以很好地反应视频在上传到YouTube之后播放流量的真实分布(一般是刚上线后流量有一个峰值,后面就迅速减少了),通过整合该特征后预测视频的分布跟真实播放分布保持一致。
2. 候选集排序
候选集排序阶段(参见下图)通过整合用户更多维度的特征,通过特征拼接获得最终的模型输入向量,灌入三层的全连接MLP神经网络,通过一个加权的logistic回归输出层获得对用户点击概率的预测,同样采用交叉熵作为损失函数。
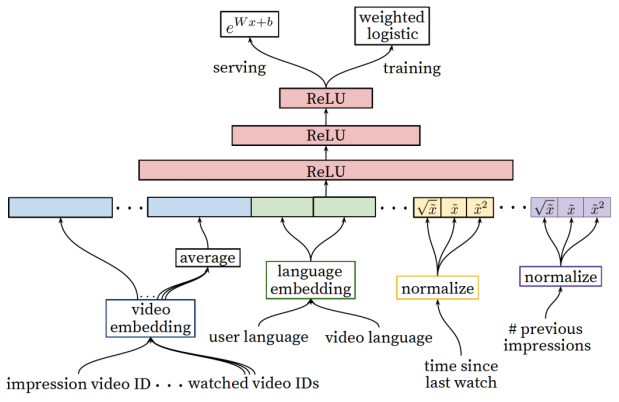
最左边的特征是待曝光的视频,右边是其他的输入特征,排序算法采用了几百个特征。其中最有用的特征还是用户的历史行为,比如,待预测的视频来自于哪个主题,用户在这个主题上看了多少视频,用户上一次看这个主题是什么时候。召回算法的输出也可以作为特征,比如,视频来自哪个召回源,召回算法计算的分数是多少。
所有特征分为类别特征和连续特征。类别特征都采用embedding向量表示。对视频生成一个词袋vocabulary,按照点击率对视频从高到底排序,取top-N的视频进入词袋,避免过于庞大的视频规模。对于搜索记录采用同样的处理方法。另外,不在词袋中的值都用0向量表示。在设计embedding维度时,维度大小与词袋中元素数量的对数成比例。
对于连续特征,需要进行规范化normalization。根据连续特征的分布,采用直方图均衡化的方式,将特征值映射到[0,1],使得映射值在[0,1]均匀分布。直方图均衡化在图像上早有应用,映射之后让像素点的值均匀分布在[0,255]之间。对于规范化后的特征x,同时加上x的二次项和开方项作为输入,以增强特征和算法模型的表达能力。
第1个特征impression video ID是当前要计算的video的embedding。第2个特征watched video IDs是用户观看过的最后N个视频的embedding的average pooling。第3个特征Language embedding是用户语言的embedding和当前视频语言的embedding。第4个特征time since last watch表示的是用户上次观看同类视频的时间。第5个特征previous impressions表示该视频已经被曝光给该用户的次数。
这里要着重说一下第4个特征和第5个特征。第4个特征用来反映用户观看同类视频的间隔时间。从用户的角度想,我们看过这类视频,就有很大概率继续看这类视频。那么该特征就很好的捕捉到了这一用户行为。而第5个特征避免了同一视频继续对同一用户进行无效曝光,尽量增加用户没看过的新视频的曝光可能性。
再介绍一下算法的目标函数。如果以点击率作为目标,可能会存在标题党,或者用户被封面图吸引,但是点开之后用户并不感兴趣。而观看时长能够真实地捕获用户的兴趣,因此youtube的预测期目标是观看时长。具体如何操作?训练集中包含正样本和负样本,正样本是用户点击并且观看的视频,负样本是曝光之后没有点击的视频。
训练时采用交叉熵loss,并且对正负样本的loss设置不同的权重,负样本设置单位权重,正样本用观看时长作为权重,如上图中输出端training支线的weighted logistic。在预测时,用指数函数作为激活函数计算期望观看时长,如上图中的serving支线。
下面我们来说明为什么这样的形式刚好是优化了用户的播放时长。
模型用加权logistic回归作为输出层的激活函数,对于正样本,权重是视频的观看时间,对于负样本权重为1。下面我们简单说明一下为什么用加权logistic回归以及serving阶段为什么要用e^(Wx+b)来预测。
logistic函数公式如下,
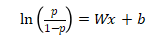
通过变换,我们得到
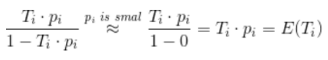
公式中约等于号成立,是因为YouTube视频总量非常大,而正样本是很少的,因此点击率pi很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过e^(Wx+b)来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。
候选集排序阶段为了让排序更加精准,利用了非常多的特征灌入模型(由于只需对候选集中的几百个而不是全部视频排序,这时可以选用更多的特征、相对复杂的模型),包括类别特征和连续特征。
Google的wide&deep深度学习推荐模型
wide & deep模型分为wide和deep两部分。wide部分是一个线性模型,学习特征间的简单交互,能够“记忆”用户的行为,为用户推荐感兴趣的内容,但是需要大量耗时费力的人工特征工作。deep部分是一个前馈深度神经网络模型,通过稀疏特征的低维嵌入,可以学习到训练样本中不可见的特征之间的复杂交叉组合,因此可以提升模型的泛化能力,并且也可以有效避免复杂的人工特征工程。通过将这两部分结合,联合训练,最终获得记忆和泛化两个优点。该模型的网络结构图如下图中间(左边是对应的wide部分,右边是deep部分)。
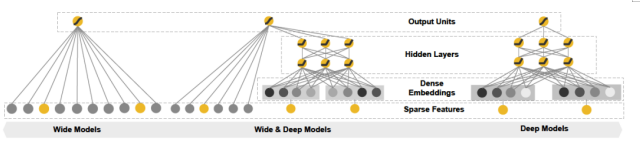
wide & deep 模型网络结构图
wide部分是一般线性模型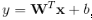 ,y是最终的预测值,这里
,y是最终的预测值,这里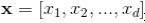 是d个特征,
是d个特征,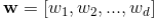 是模型参数,b是bias。这里的特征X包含两类特征:
是模型参数,b是bias。这里的特征X包含两类特征:
(1) 原始输入特征;
(2) 通过变换后(交叉积)的特征;
这里的用的主要变换是交叉积(cross-product),它定义如下:

公式中cki是布尔型变量,如果第i个特征xi是第k个变换的一部分,那么cki=1,否则为0。对于交叉积And(gender=female, language=en),只有当它的成分特征都为1时,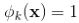 ,否则
,否则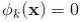 。
。
deep部分是一个前馈神经网络模型,高维类别特征通过先嵌入到低维空间(几十上百维)转化为稠密向量, 再灌入深度学习模型中。神经网络中每层通过计算公式
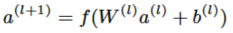
与上层进行数据交互。上式中l是层数,f是激活函数(该模型采用了ReLU),W^(l)、b^(l) 是模型需要学习的参数。
最终wide和deep部分需要结合起来,通过将他们的的对数几率加权平均,再喂给logistic损失函数进行联合训练。最终我们通过如下方式来预测用户的兴趣偏好(这里也是将预测看成是二分类问题,预测用户的点击概率)。
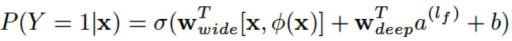
这里,Y是最终的二元分类变量,∂是sigmoid函数,∅(x)是前面提到的交叉积特征,Wwide和Wdeep分别是wide模型的权重和deep模型中对应于最后激活a^(lf)的权重。
下图是最终的wide & deep模型的整体结构,类别特征是嵌入到32维空间的稠密向量,数值特征归一化到0-1之间(本文中归一化采用了该变量的累积分布函数,再通过将累积分布函数分成若干个分位点,用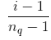 来作为该变量的归一化值,这里nq是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP评分(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试(为同一个优化目标,制定两个方案,让一部分用户使用A方案,同时另一部分用户使用B方案,统计并对比不同方案的各个指标,以判断不同方案的优劣,从而优化)。
来作为该变量的归一化值,这里nq是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP评分(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试(为同一个优化目标,制定两个方案,让一部分用户使用A方案,同时另一部分用户使用B方案,统计并对比不同方案的各个指标,以判断不同方案的优劣,从而优化)。
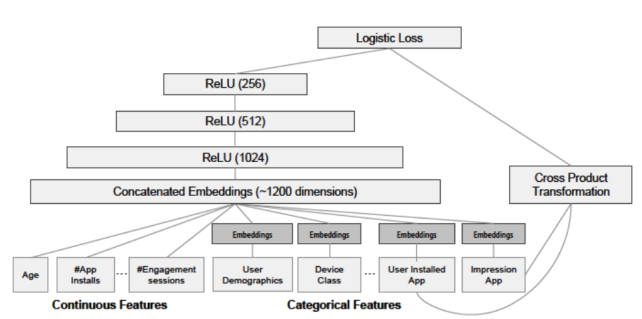
wide & deep 模型的数据源于具体网络结构图
阿里基于兴趣树(TDM)的深度学习推荐算法
通过利用从粗到精的方式从上到下检索兴趣树的节点为用户生成推荐候选集,该方法可以从海量商品中快速(检索时间正比于商品数量的对数,因此是一类高效的算法)检索出topN用户最感兴趣的商品。下面我们对该算法的基本原理做简单介绍,算法一共分为如下3个主要步骤。
1. 构建兴趣树
构建树模型分为两种情况,首先是初始化树模型,有了树模型会经过深度学习模型学习树中叶子节点的嵌入表示,有了嵌入表示后再重新优化新的树模型。下面分别讲解初始化树模型和获得了叶子节点的嵌入表示后重新构建新的树模型。
初始化树模型的思路是希望将相似的物品放到树中相近的地方(见下图)。由于开始没有足够多的信息,这时可以利用物品的类别信息,同一类别中的物品一般会比不同类别的物品更相似。假设一共有k个类别,我们将这k个类别随机排序,排序后为C_1、C_2、...... 、C_k,每一类中的物品随机排序,如果一个物品属于多个类别,那么将它分配到所属的任何类别中,确保每个商品分配的唯一性。那么通过这样处理,就变为下图中的最上面一层这样的排列。这时可以找到这一个物品队列的中点(下图最最上一层的红竖线),从中间将队列均匀地分为两个队列(见下图第二层的节点),这两个队列再分别从中间分为两个队列,递归进行下去,直到每个队列只包含一个物品为止,这样就构建出了一棵(平衡)二叉树,得到了初始化的兴趣树模型。
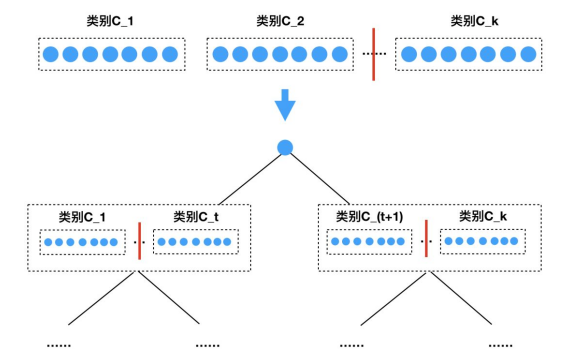
初始化树模型
如果有了兴趣树叶子节点的嵌入向量表示,我们可以基于该向量表示利用聚类算法构建一棵新的兴趣树,具体流程如下:利用kmeans将所有商品的嵌入向量聚类为2类,并对这两类做适当调整使得最终构建的兴趣树更加平衡(这两类中的商品差不多一样多),并对每一类再采用kmeans聚类并适当调整保持分的两类包含的商品差不多一样多,这个过程一直进行下去,直到每类只包含一个商品,这个分类过程就构建出了一棵平衡的二叉树。由于是采用嵌入向量进行的kmeans聚类,被分在同一类的嵌入向量相似(欧几里得距离小),因此,构建的兴趣树满足相似的节点放在相近的地方。
2.学习兴趣树叶子节点的嵌入表示
在讲兴趣树模型训练之前,先说下该兴趣树的需要满足的特性。对于树中第j层的每个非叶子节点,满足如下公式:

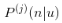 是用户u对商品n感兴趣的概率,a^(j)是层j的归一化项,保证该层所有节点的概率加起来等于1。上式的意思是某个非叶子节点的兴趣概率等于它的子节点中兴趣概率的最大值除以归一化项。
是用户u对商品n感兴趣的概率,a^(j)是层j的归一化项,保证该层所有节点的概率加起来等于1。上式的意思是某个非叶子节点的兴趣概率等于它的子节点中兴趣概率的最大值除以归一化项。
为了训练树模型,我们需要确定树中每个节点是否是正样本节点和负样本节点,下面说明怎么确定它们。如果用户喜欢某个叶子节点(即喜欢该叶子节点对应的商品,即用户对该商品有隐式反馈),那么该叶子节点从下到上沿着树结构的所有父节点都是正样本节点。因此,该用户所有喜欢的叶子节点及对应的父节点都是正样本节点。对于某一层除去所有的正样本节点,从剩下的节点中随机选取节点作为负样本节点,这个过程即是负采样。参考下面图6中右下角中的正样本节点和负样本节点。
记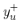 和
和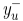 分别为用户u的正、负样本集。该模型的似然函数为
分别为用户u的正、负样本集。该模型的似然函数为

这里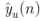 是用户u对物品n的喜好label(=0或者=1),
是用户u对物品n的喜好label(=0或者=1),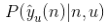 是
是![]() =1或
=1或 =0对应的概率。对所有用户u和商品n,我们可以获得对应的模型损失函数,具体如下
=0对应的概率。对所有用户u和商品n,我们可以获得对应的模型损失函数,具体如下
有了上面的背景解释,兴趣树中叶子节点(即所有商品集)的嵌入表示可以通过下图的深度学习模型来学习(损失函数就是上面的损失函数)。用户的历史行为按照时间顺序被划分为不同的时间窗口,每个窗口中的商品嵌入最终通过加权平均(权重从Activation Unit获得,见下图右上角的Activation Unit模型)获得该窗口的最终嵌入表示。所有窗口的嵌入向量外加候选节点(即正样本和负采样的样本)的嵌入向量通过拼接,作为最上层神经网络模型的输入。最上层的神经网络是3层全连接的带PReLU激活函数的网络结构,输出层是2分类的softmax激活函数,输出值代表的是用户对候选节点的喜好概率。每个叶子节点拥有一样的嵌入向量,所有嵌入向量是随机初始化的。
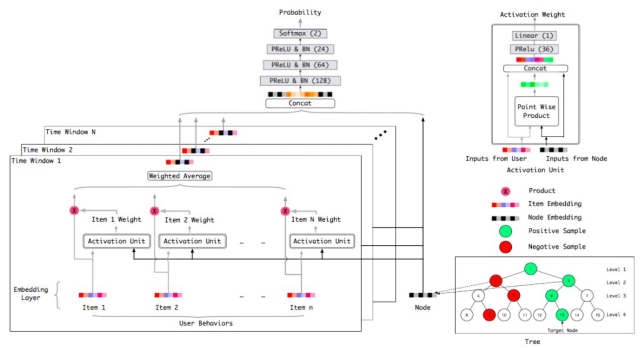
BST推荐模型网络结构图
3. 从树中检索出topN最喜欢的商品
通过上面两步求得最终的兴趣树后,我们可以非常容易的检索出topN用户最喜欢的商品作为推荐候选集,具体流程如下:
采用自顶向下的方式检索(如下图,并且假设我们取top2候选集,对于更多候选集过程是一样的)。从根节点1出发,从level2中取两个兴趣度最大的节点(从2中介绍可以知道,每个节点是有一个概率值来代表用户对它的喜好度的),这里是2、4两个节点(用红色标记了,下面也是一样)。再分别对2、4两个节点找他们兴趣度最大的两个子节点,2的子节点是6、7,而4的子节点是11、12,从6、7、11、12这4个level3层的节点中选择两个兴趣度最大的,这里是6,11。再选择6、11的两个兴趣度最大的子节点,分别是14、15和20、21,最后从14、15、20、21这四个level4层的节点中选择2个兴趣度最大的节点(假设是14、21)作为给用户的最终候选推荐,所以最终top2的候选集是14、21。
在实际生成候选集推荐之前,可以事先对每个节点关联一个N个元素的最大堆(即该节点兴趣度最大的N个节点),将所有非叶子节点的最大堆采用Key-Value的数据结构存起来。在实际检索时,每个非叶子节点直接从关联的最大堆中获取兴趣度最大的N个子节点。因此,整个搜索过程是非常高效的。
通过树模型检索,可以大大减少检索时间,避免了从海量商品库中全量检索的低效率情况,因此,该模型非常适合有海量标的物的产品的推荐候选集生成过程。
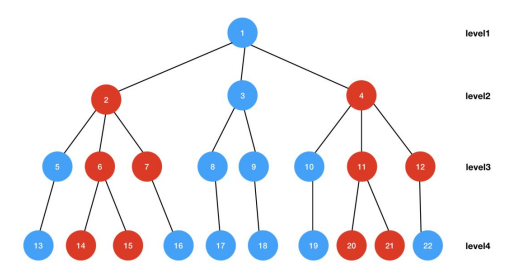
从兴趣树中检索出topN用户最喜欢的商品