深度学习介绍
深度学习其实就是神经网络模型,一般来说,隐含层数量大于等于2层就认为是深度学习(神经网络)模型。神经网络不是什么新鲜概念,在好几十年前就被提出来了,最早可追溯到1943年McCulloch与Pitts合作的一篇论文(参考文献1),神经网络是模拟人的大脑中神经元与突触之间进行信息处理与交互的过程而提出的。神经网络的一般结构如下图,一般分为输入层、隐含层和输出层三层,其中隐含层可以有多层,各层中的圆形是对应的节点(模拟神经元的对应物),节点之间通过有向边(模拟神经元之间的突触)连接,所以神经网络也是一种有向图模型。
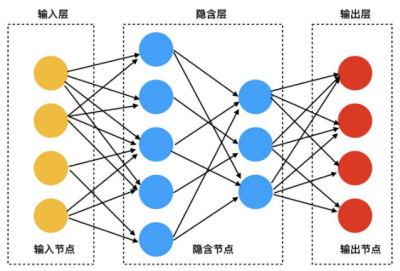
图1:深度学习网络(前馈神经网络)结构示意图
偏置节点(bias unit)是默认存在的。它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。一般情况下,我们都不会明确画出偏置节点。
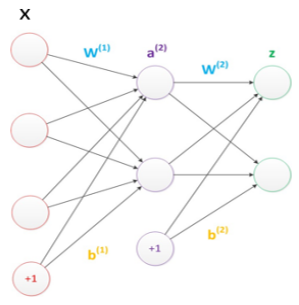
图2:偏置节点示意图
假设前馈神经网络一共有k个隐含层,那么我们可以用如下一组公式来说明数据沿着箭头传递的计算过程,其中 是输入, 是第i个隐含层各个节点对应的数值,是从第i-1层到第i层的权重矩阵,是偏移量,是激活函数,是最终的输出,这里、是需要学习的参数。
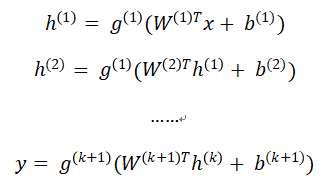
深度学习一般应用于回归、分类等监督学习问题,通过输出层的损失函数,构建对应的最优化问题,深度学习借助于反向传播(参考文献2)技术来进行迭代优化,将预测误差从输出层向输入层(即反向)传递,依次更新各层的网络参数,通过结合某种参数更新的最优化算法(一般是各种梯度下降算法),实现参数的调整和更新,最终通过多伦迭代让损失函数收敛到(局部)最小值,从而求出模型参数。