
智一面的面试题提供python的测试题
使用地址:http://www.gtalent.cn/exam/interview?token=09b2a6b63e829ef00c112d80fe78d1df
Part1 进行网页分析
首先打开网易云的网页版网易云
然后搜索歌曲,这里我就搜索一首锦零的“空山新雨后”
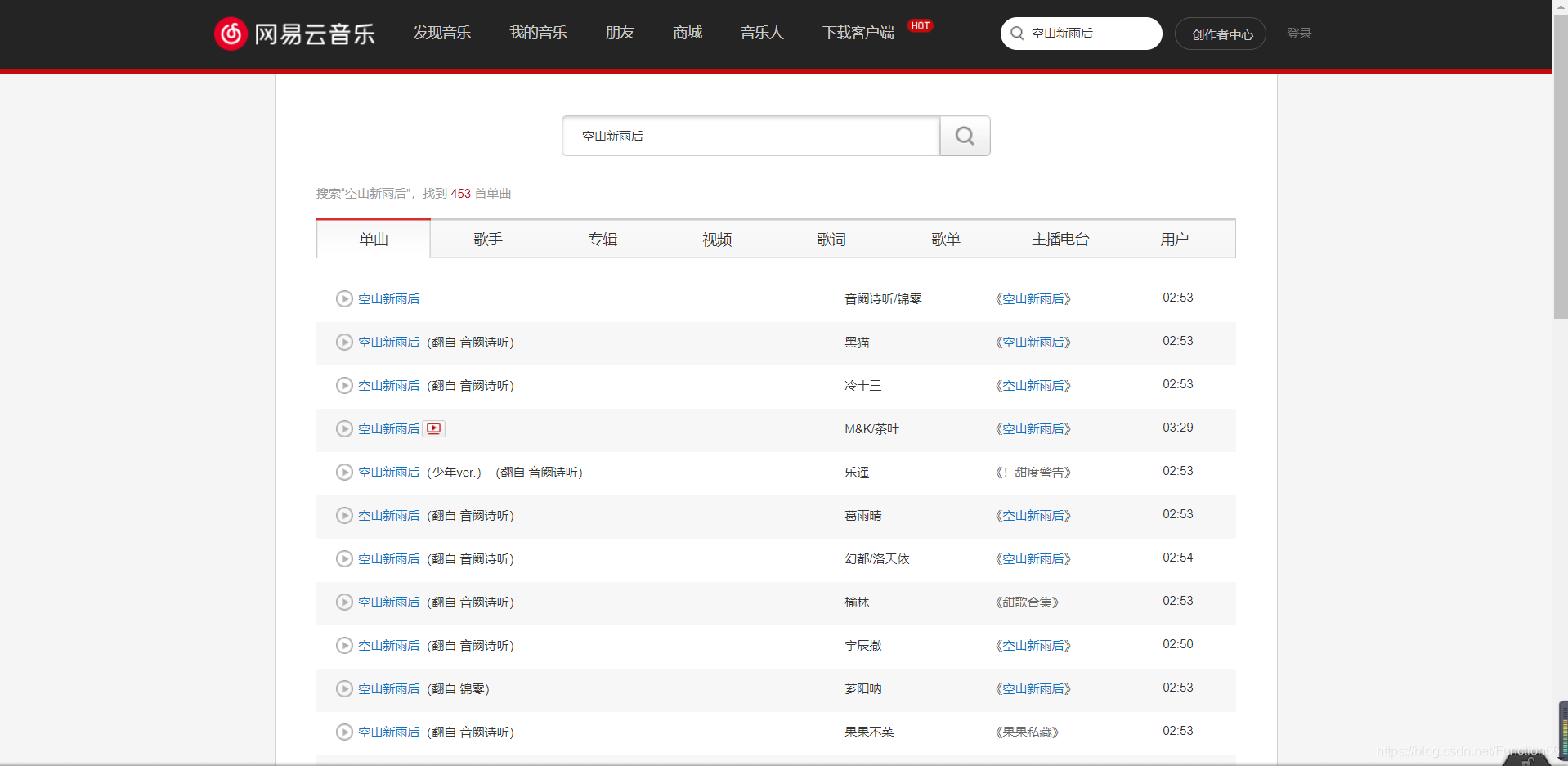
这时我们来观察网页的url,可以发现s=后面就是我们搜索的关键字
当我们换一首歌,会发现也是这样的,正好验证了我们的想法
所以下一步让我们点进去一首歌,然后进行播放,看看能否直接获取音乐文件的url,如果能,那么直接对url进行requests.get访问,我们就能拿到.mp3文件了
点进第一首“空山新雨后”,我们可以看到有一个“生成外链播放器”
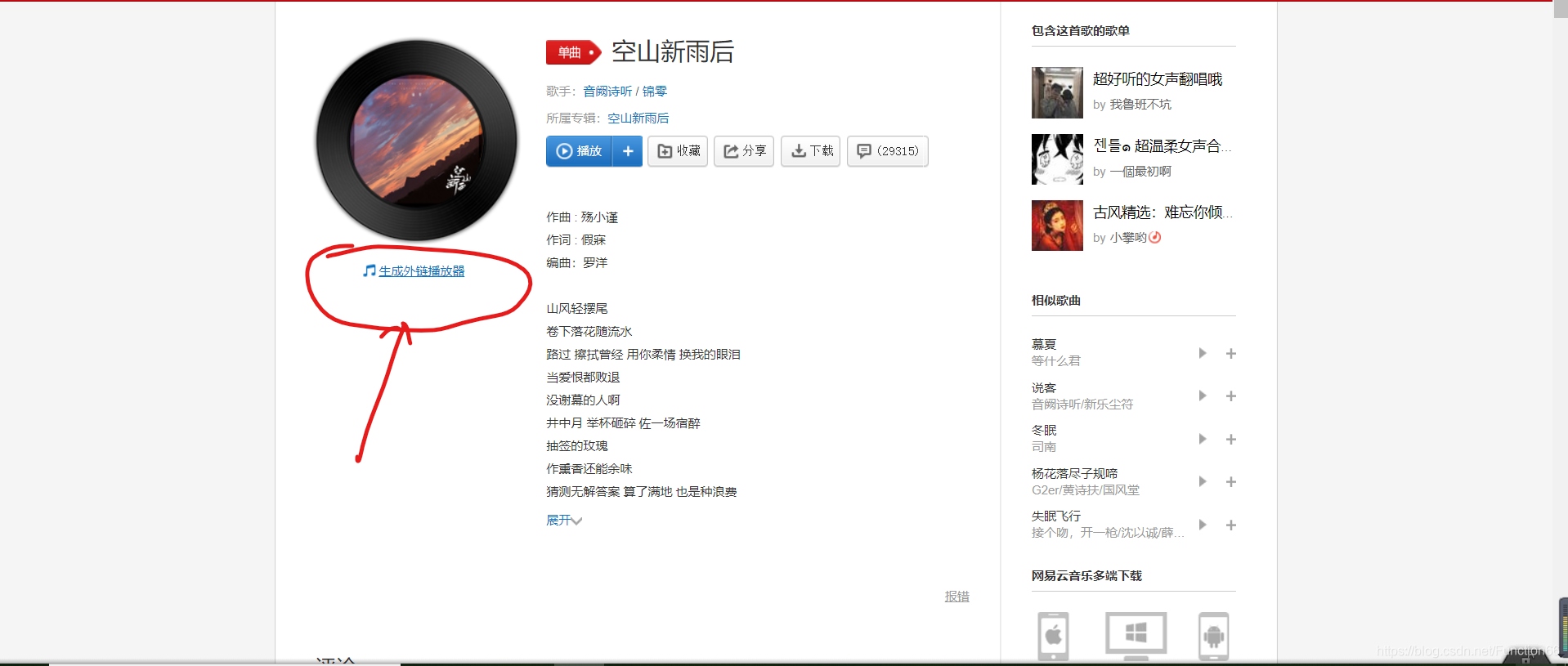
————————————————
看到这个,我心中一阵激动,仿佛就要大功告成;于是我满怀开心的点了一下,结果。。。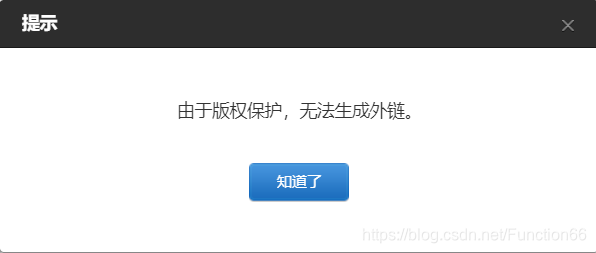
好吧,不过我们不能放弃,来我们分析一下网页
但当我们定位到两个最有可能出现外链的地方时,发现什么都没有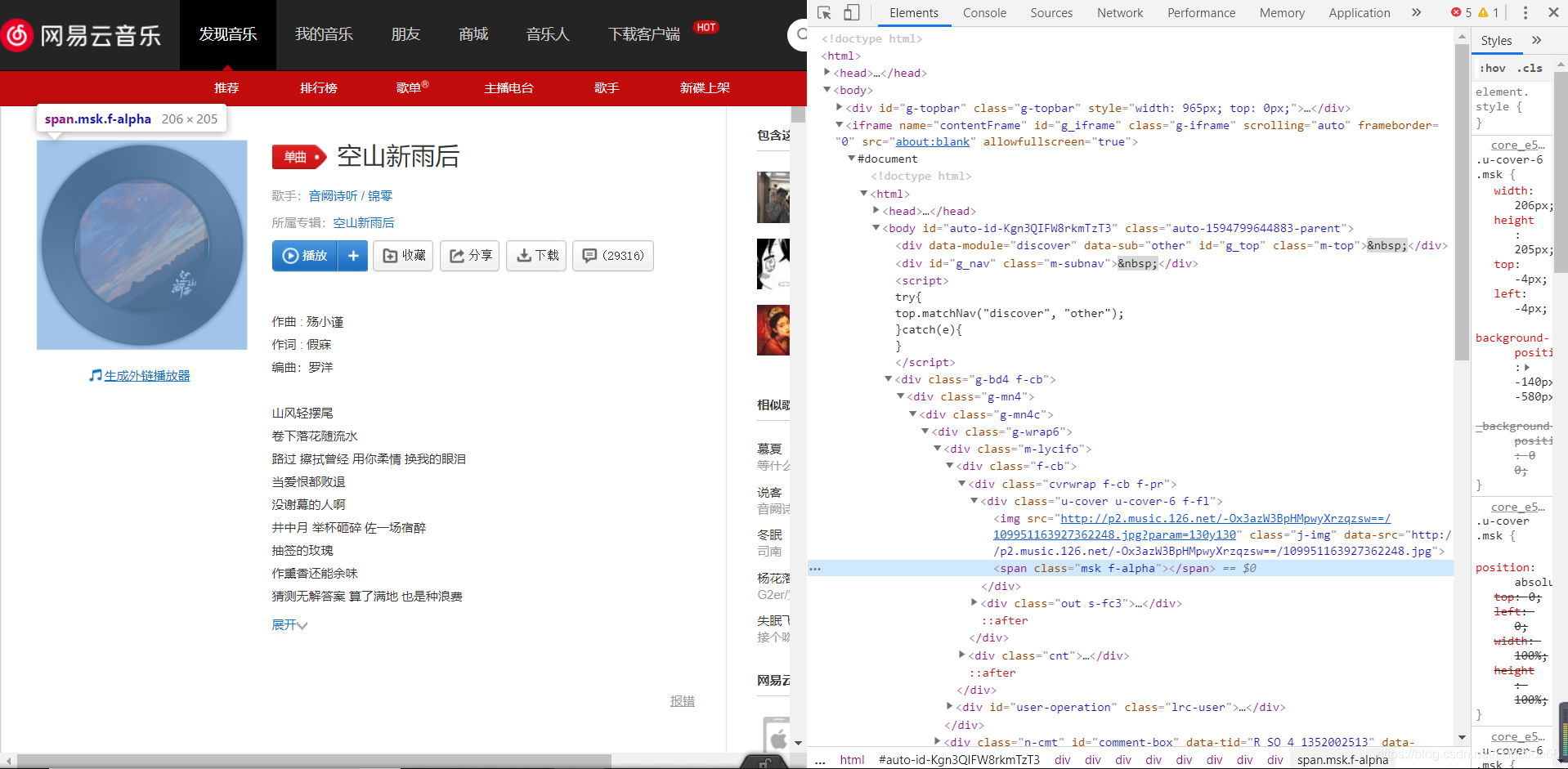 不过作为“规格严格,功夫到家”的传承者,我不能放弃啊,于是我又打开了抓包工具
不过作为“规格严格,功夫到家”的传承者,我不能放弃啊,于是我又打开了抓包工具
按照常规套路,我们定位到XHR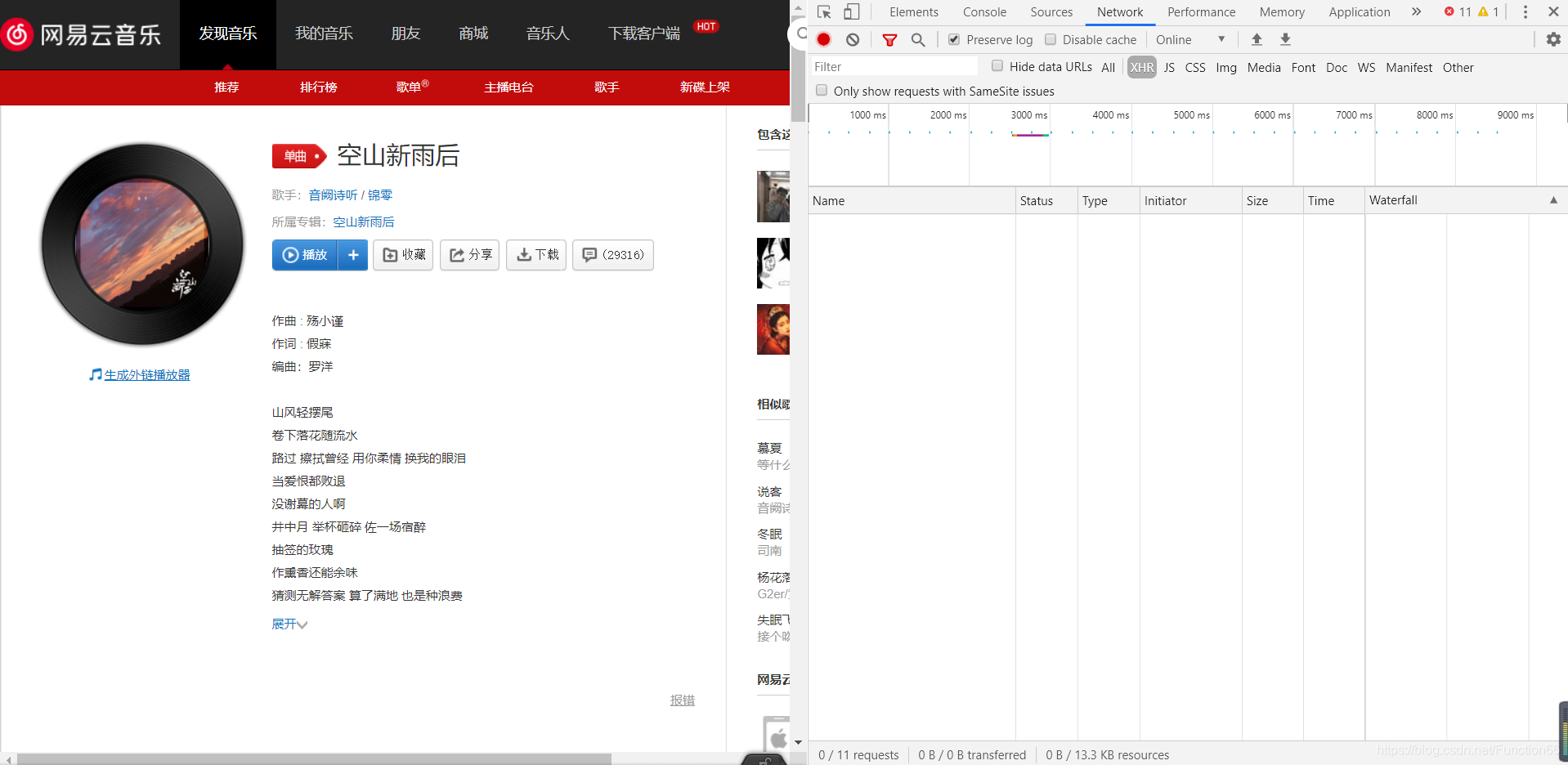
点击播放后,出现了一大堆东西,我们要做的就是找到其中的content-type为audio一类的包
功夫不负有心人,在寻找了一(亿)会儿后,我找到了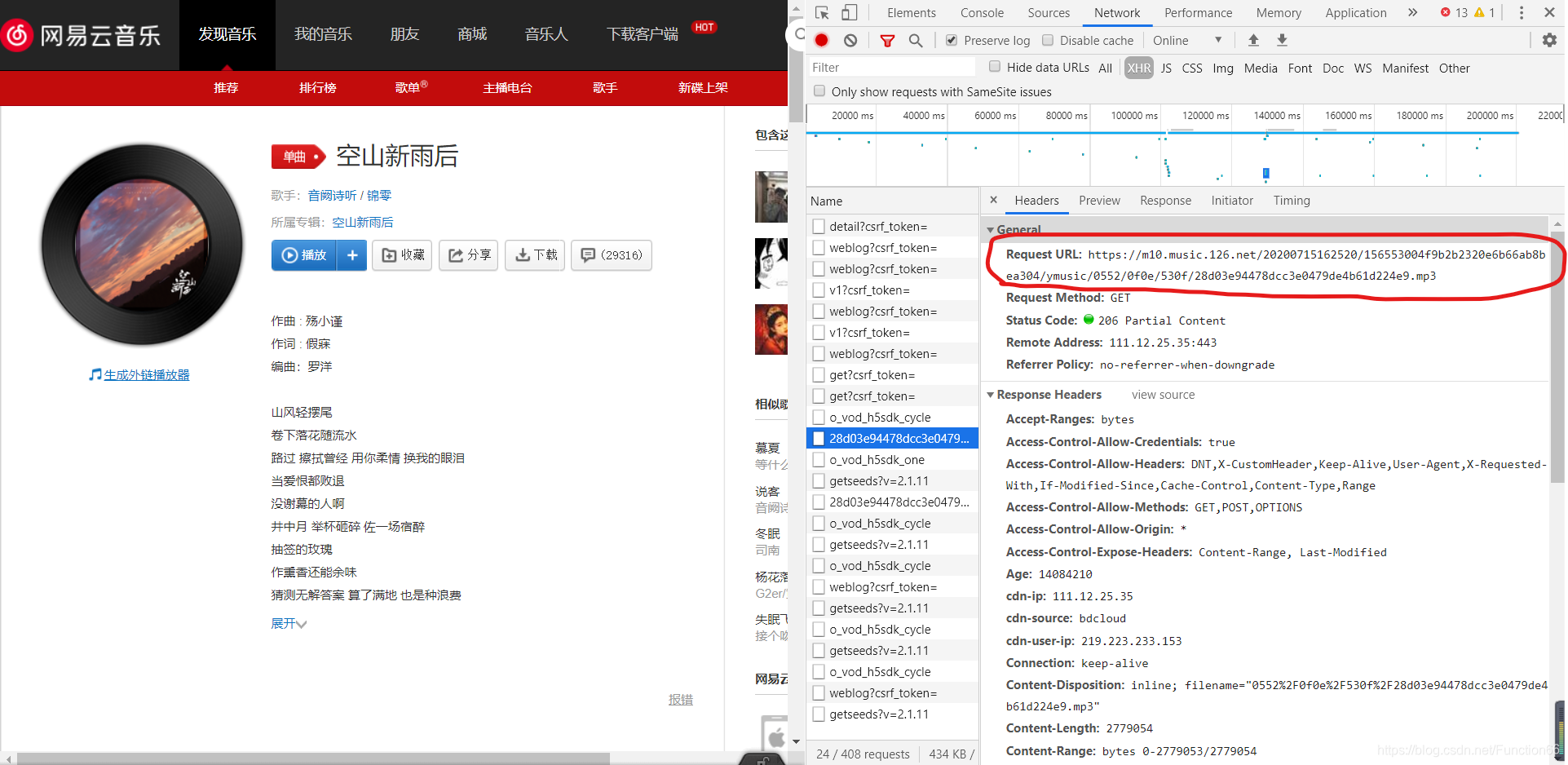
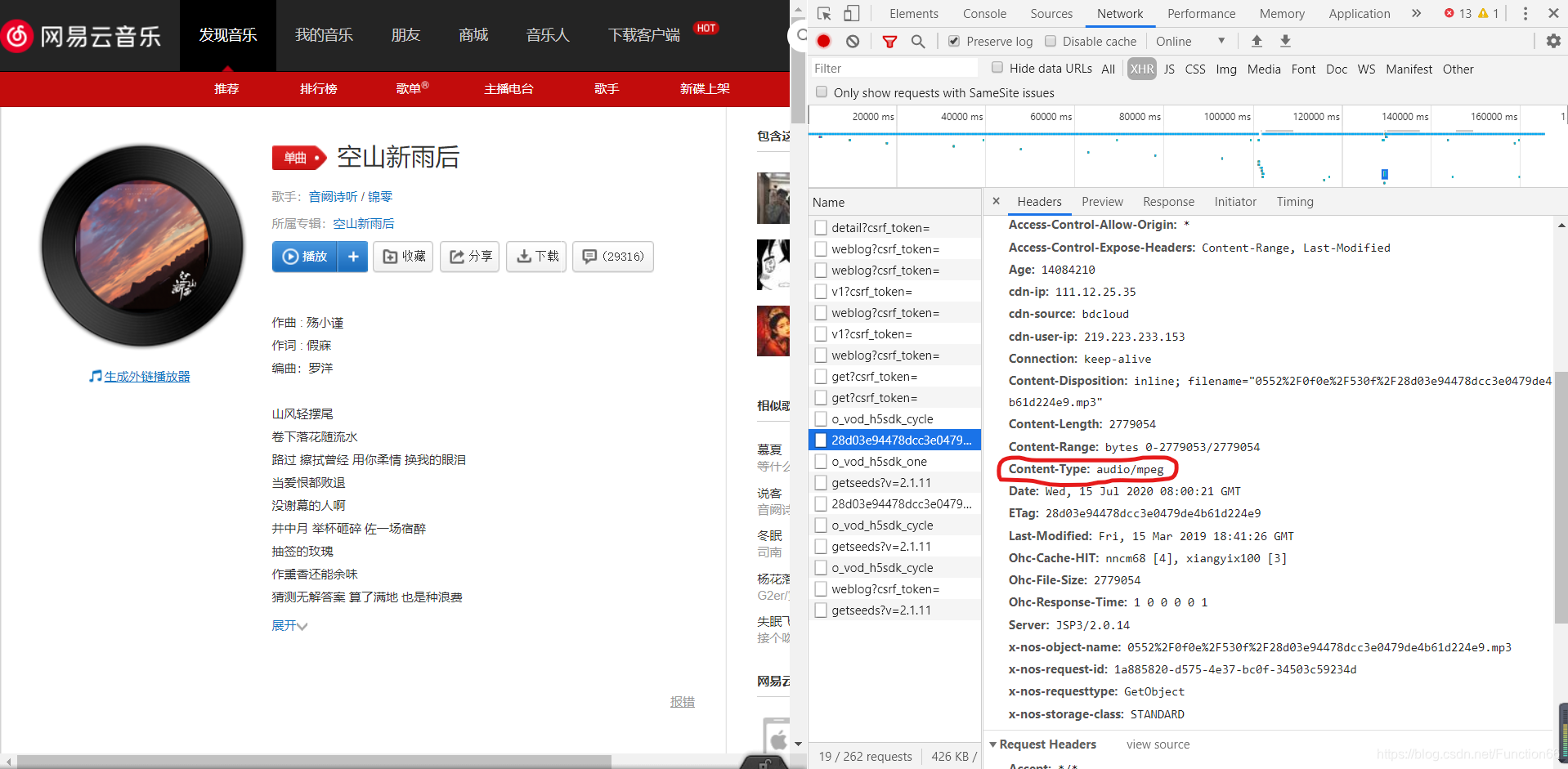
于是我又满怀开心的复制了这个包对应的Request-URL

现在我把那个url贴出来
https://m10.music.126.net/20200715163315/a075d787d191f6729a517527d6064f59/ymusic/0552/0f0e/530f/28d03e94478dcc3e0479de4b61d224e9.mp3
Part2 编写爬虫程序
接下来就超级简单了
下面的代码是最常规的操作,应该有爬虫基础的都能看懂;如果有不懂的,注释都在上面
#导入requests包
import requests
#进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
#指定url
url = 'https://m10.music.126.net/20200715163315/a075d787d191f6729a517527d6064f59/ymusic/0552/0f0e/530f/28d03e94478dcc3e0479de4b61d224e9.mp3'
#调用requests.get方法对url进行访问,和持久化存储数据
audio_content = requests.get(url=url,headers=headers).content
#存入本地
with open('空山新雨后.mp3','wb') as f :
f.write(audio_content)
print("空山新雨后爬取成功!!!")
————————————————
Part3 更高级的
看到这里,你可能会想,为啥根本没用selenium模块呢?能不能直接爬取任何一首我想要的歌,而不用每首都去费心费力的找一个url呢?当然可以哒!
其实网易云在线播放每首歌曲时,都有一个外链地址,这是不会变的,跟每首歌的唯一一个id绑定在一起,每首歌audio文件的url如下:
url = 'http://music.163.com/song/media/outer/url?id=' + 歌曲的id值 + '.mp3'
id值的获取也很简单,当我们点进每首歌时,上方会出现对应的网址,那里有id值,如下图: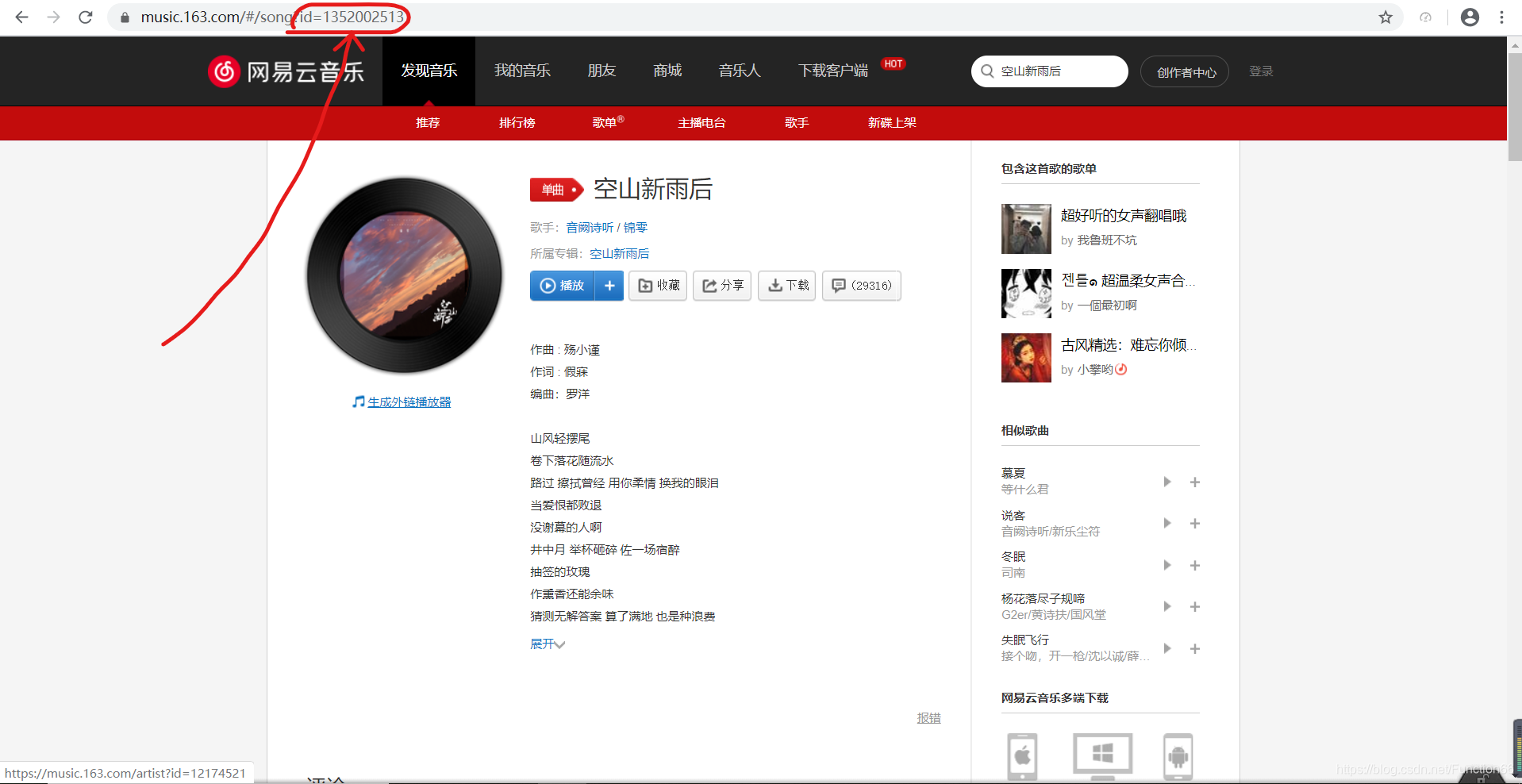
所以只需把上面程序中的url改成新的url即可
如果还想要更好的体验效果,实现在程序里直接搜索歌曲,拿到id值,就需要用到selenium模块
为什么用selenium而不用xpath或bs4?
因为搜索页面的数据是动态加载出来的,如果直接对搜索页面的网页进行数据解析,就拿不到任何数据;以我目前的技术,就只能想到使用万能的selenium模块,下面大概说明一下步骤:
进行selenium无可视化界面设置
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
导包
import requests
import re
from selenium import webdriver
from time import sleep
指定歌曲,得到对应搜索页面的url
name = input('请输入歌名:')
url_1 = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
获取搜索页面的html文件
#初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
#访问该url
browser.get(url=url_1)
#由于网页中有iframe框架,进行切换
browser.switch_to.frame('g_iframe')
#等待0.5秒
sleep(0.5)
#抓取到页面信息
page_text = browser.execute_script("return document.documentElement.outerHTML")
#退出浏览器
browser.quit()
用正则模块re匹配html文件中的id值、歌名和歌手
ex1 = '<a.*?id="([0-9]*?)"'
ex2 = '<b.*?title="(.*?)"><span class="s-fc7">'
ex3 = 'class="td w1"><div.*?class="text"><a.*?href=".*?">(.*?)</a></div></div>'
id_list = re.findall(ex1,page_text,re.M)[::2]
song_list = re.findall(ex2,page_text,re.M)
singer_list = re.findall(ex3,page_text,re.M)
将id值、歌名和歌手封装成一个个元组,写入一个列表中,再进行打印
li = list(zip(song_list,singer_list,id_list))
for i in range(len(li)):
print(str(i+1) + '.' + str(li[i]),end='\n')
对满意的id值可得到一个url,再用上面的程序对该url进行requests.get方法访问即可
Part4 小结
终究是我才疏学浅,这个找外链进行爬取的方法也存在很多不足,比如不能在线播放的歌曲是无法下载的。
不过写这样一个小程序练练手,对自己能力的提高确是有极大帮助的。
————————————————
我们的python技术交流群:941108876
智一面的面试题提供python的测试题
使用地址:http://www.gtalent.cn/exam/interview?token=c7dcd205a4fdab0d6e8ca200b31b3489