Uber 的 Kafka 生态系统
Uber 拥有世界上最大的 Kafka 集群,每天处理数万亿条消息和几个 PB 的数据。如图 1 所示,Kafka 现在成了 Uber 技术栈的基石,我们基于这个基石构建了一个复杂的生态系统,为大量不同的工作流提供支持。其中包含了一个用于传递来自乘客和司机 App 事件数据的发布 / 订阅消息总线、为流式分析平台(如 Apache Samza、Apache Flink)提供支持、将数据库变更日志流到下游订阅者,并将各种数据接收到 Uber 的 Hadoop 数据湖中。
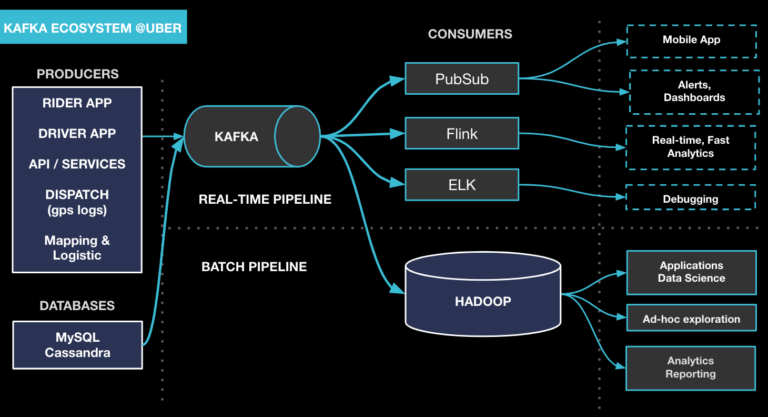
图 1:Uber 的 Kafka 生态系统
为了能够基于 Kafka 构建一个可伸缩、可靠、高性能、易于使用的消息传递平台,我们克服了许多挑战。在这篇文章中,我们将着重介绍在进行灾难恢复(因集群宕机导致)时所面临的一个挑战,并分享我们如何构建一个多区域的 Kafka 基础设施。
Uber 的 Kafka 多区域部署
提供业务弹性和连续性是 Uber 的首要任务。我们制定了详细的灾难恢复计划,尽量减少自然和人为灾难 (如停电、灾难性软件故障和网络中断) 对业务的影响。我们采用多区域部署策略,将服务与备份一起部署在分布式的数据中心中。当一个区域的物理基础设施不可用时,服务仍然可以在其他区域运行。
我们构建了一个多区域 Kafka 架构,实现了数据冗余,为区域故障转移提供支持。Uber 技术栈中的很多服务都依赖 Kafka 来实现区域级故障转移。这些服务是 Kafka 的下游,并假定 Kafka 中的数据是可用且可靠的。
图 2 描绘了多区域 Kafka 架构。我们有两种集群:生产者在本地向区域集群发布消息,将来自区域集群的消息复制到聚合集群,以此来提供全局视图。为简单起见,图 2 只显示了两个区域的集群。
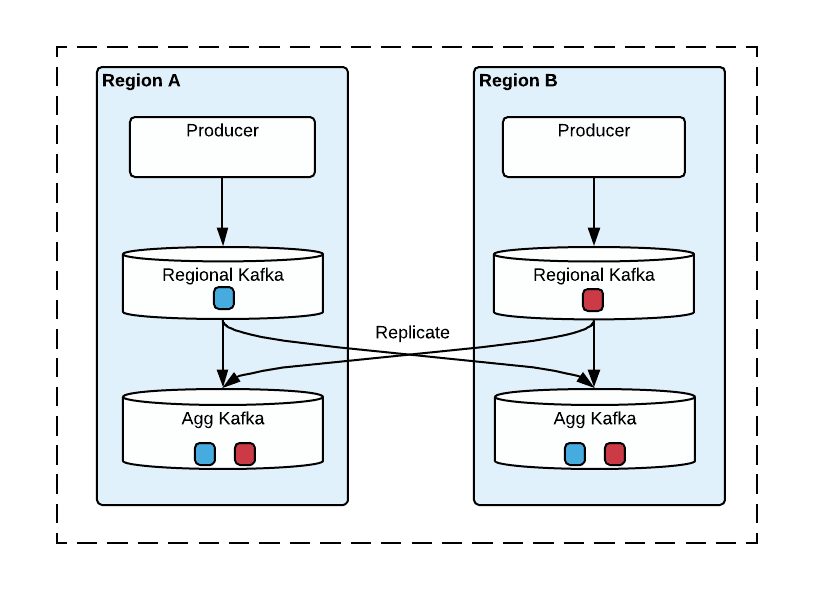
图 2:两个区域之间的 Kafka 复制拓扑
在每个区域,生产者总是在本地生产消息,以便获得更好的性能,当 Kafka 集群不可用时,生产者会转移到另一个区域,然后向该区域的区域集群生产消息。
这个架构中的一个关键部分是消息复制。消息从区域集群异步复制到其他区域的聚合集群。我们开发了 uReplicator(https://eng.uber.com/ureplicator)
——Uber 的 Kafka 数据复制解决方案,健壮且可靠。uReplicator 扩展了 Kafka 的 MirrorMaker,专注于可靠性、零数据丢失保证和易维护性。
从多区域 Kafka 集群消费消息
从多区域集群消费消息比生产消息更为复杂。多区域 Kafka 集群支持两种类型的消费模式。
双活模式
一种常见的类型是双活(Active/Active)消费模式,消费者在各自区域中消费聚合集群的主题。Uber 的很多应用程序使用这种模式消费多区域 Kafka 集群里的消息,而不是直接连接到其他区域。当一个区域发生故障时,如果 Kafka 流在两个区域都可用,并且包含了相同的数据,那么消费者就会切换到另一个区域。
例如,图 3 显示了 Uber 的动态定价服务 (即峰时定价) 如何使用双活模式来构建灾备计划。价格是根据附近地区最近一系列打车数据来计算的。所有的打车事件都被发送到 Kafka 区域集群,然后聚合到聚合集群中。然后,在每个区域,一个复杂的、占用大量内存的 Flink 作业负责计算不同区域的价格。接下来,一个全活服务负责协调各个区域的更新服务,并分配一个区域作为主区域。主区域的更新服务将定价结果保存到双活数据库中,以便进行快速查询。
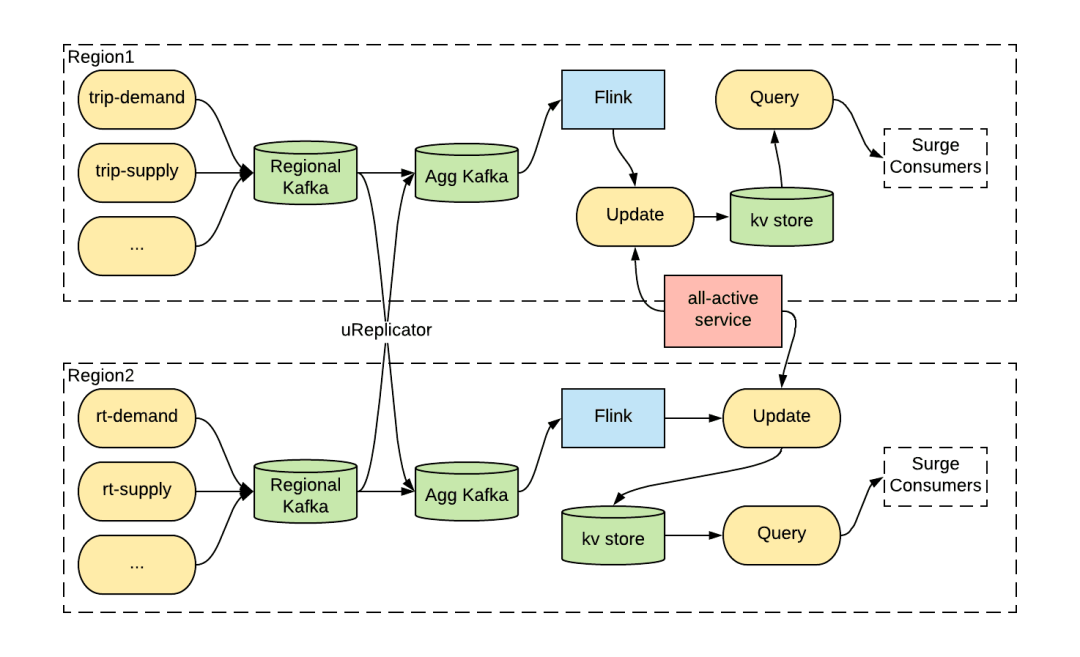
图 3:双活消费模式架构
当主区域发生灾难时,双活服务会将另一个区域作为主区域,峰时价格计算会转移到另一个区域。需要注意的是,Flink 作业的计算状态规模太大了,无法在区域之间同步复制,因此必须使用聚合集群的输入消息来计算其状态。
我们从实践中获得了一个很关键的经验,可靠的多区域基础设施服务(如 Kafka)可以极大地简化应用程序针对业务连续性计划的开发工作。应用程序可以将状态存储在基础设施层中,从而变成无状态的,将状态管理的复杂性 (如跨区域的同步和复制) 留给基础设施服务。
主备模式
另一种多区域消费模式是主备模式(Active/Passive):一次只允许一个消费者 (通过唯一名称标识) 从一个区域 (即主区域) 的聚合集群中消费消息。多区域 Kafka 集群跟踪主区域的消费进度(用偏移量表示),并将偏移量复制到其他区域。在主区域出现故障时,消费者可以故障转移到另一个区域并恢复消费进度。主备模式通常被支持强一致性的服务 (如支付处理和审计) 所使用。
在使用主备模式时,区域间消费者的偏移量同步是一个关键问题。当用户故障转移到另一个区域时,它需要重置偏移量,以便恢复消费进度。由于 Uber 的很多服务不能接受数据丢失,所以消费者无法从高水位 (即最新消息) 恢复消费。另外,为了避免过多的积压,消费者也不能从低水位 (即最早的消息) 恢复消费。此外,从区域集群聚合到聚合集群的消息可能会变得无序。由于跨区域复制延迟,消息从区域集群复制到本地聚合集群的速度比远程聚合集群要快。因此,聚合集群中的消息顺序可能会不一样。例如,在图 4a 中,消息 A1、A2、B1、B2 几乎是同时发布到区域 A 和区域 B 的区域集群中,但经过聚合后,它们在两个聚合集群中的顺序是不一样的。
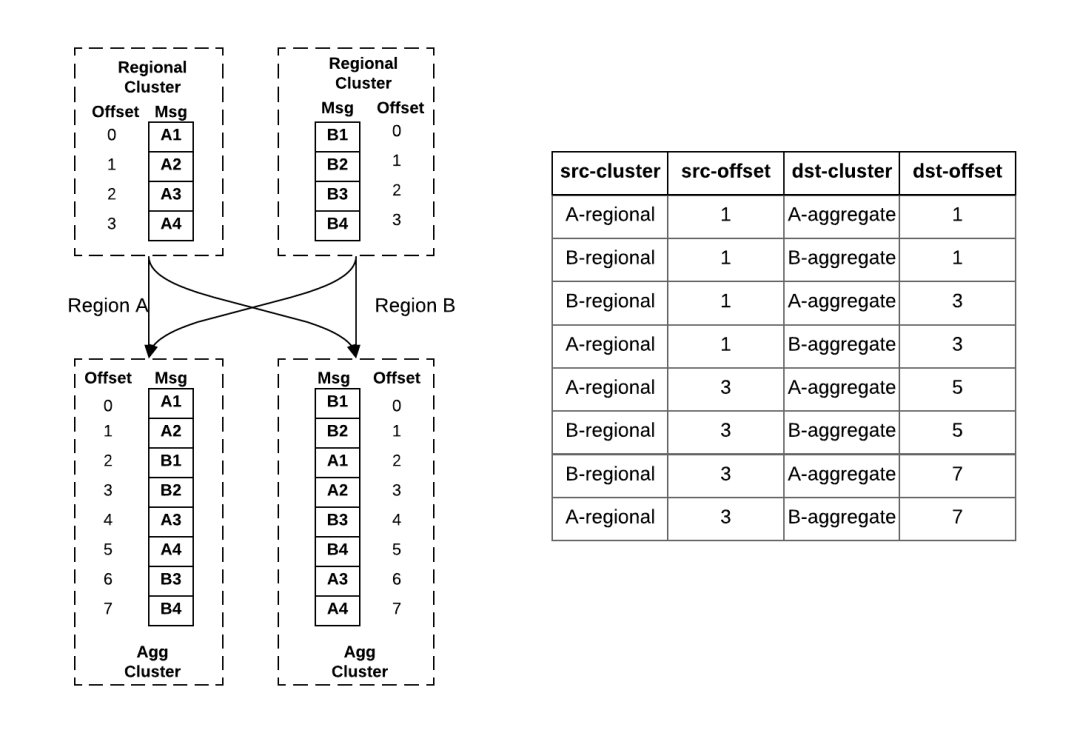
图 4:a. 跨区域消息复制 b. 消息复制检查点
为了管理这些区域的偏移量映射,我们开发了一个复杂的偏移量管理服务,架构如图 5 所示。当 uReplicator 将消息从源集群复制到目标集群时,它会定期检查从源到目标的偏移量映射。例如,图 4b 显示了图 4a 消息复制的偏移量映射。表的第一行记录了区域 A 区域集群的消息 A2(在区域集群中的偏移量是 1)映射到区域 A 聚合集群的消息 A2(在聚合集群中的偏移量是 1)。同样,其余行记录了其他复制路线的检查点。
偏移量管理服务将这些检查点保存在双活数据库中,并用它们来计算给定的主备消费者的偏移量映射。同时,一个偏移量同步作业负责定期同步两个区域之间的偏移量。当一个主备消费者从一个区域转移到另一个区域时,可以获取到最新的偏移量,并用它来恢复消费。
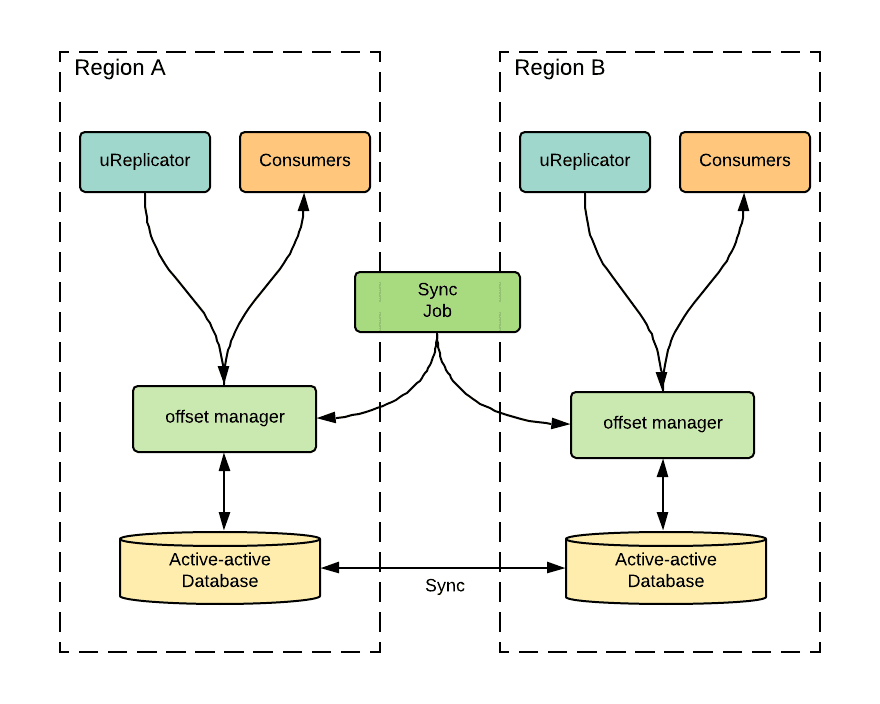
图 5:偏移量管理服务架构
偏移量映射算法的工作原理如下:在活跃的消费者正在消费的聚合集群中找到每个区域集群的最近检查点。然后,对于每个区域检查点的源偏移量,找到它们在另一个区域聚合集群对应的检查点。最后,在另一个区域的聚合集群中取最小的那个偏移量。
在图 6 中,假设活跃消费者目前的进度是区域 B 的 A3 消息(偏移量为 6)。根据右边的表检查点,最近的两个检查点分别是偏移量为 3(蓝色) 的 A2 和偏移量为 5(红色) 的 B4,分别对应区域集群 A 中偏移量 1(蓝色)和区域集群 B 的偏移量 3(红色)。这些源偏移量映射到区域 A 聚合集群的偏移量 1(蓝色) 和偏移量 7(红色)。根据算法,被动消费者 (黑色) 取两者中较小的偏移量,即偏移量 1。
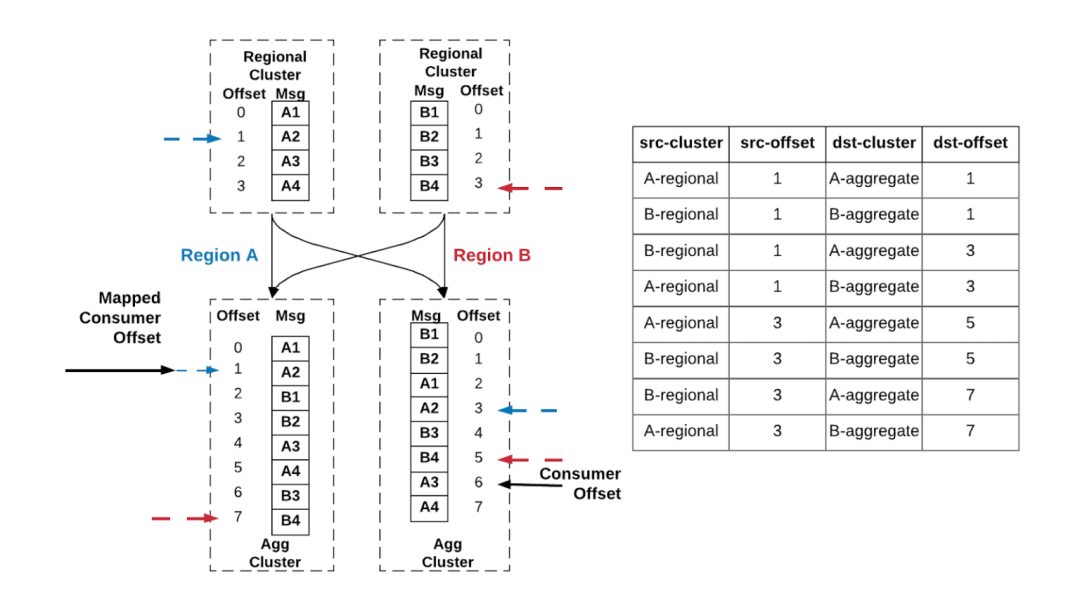
图 6:主备消费者从一个区域失效转移到另一个区域
结论
在 Uber,业务的连续性取决于高效、不间断的跨服务数据流,Kafka 在公司的灾备计划中扮演着关键角色。在这篇文章中,我们简要地强调了在 Uber 多区域 Kafka 集群的总体架构,以及当灾难发生时不同区域的故障转移策略。但是,我们还有更具挑战性的工作要做,目前要解决如何在不进行区域故障转移的情况下容忍单个集群故障的细粒度恢复策略。