
你知道一个sql语句是如何执行的吗?
首先,我们得了解mysql架构
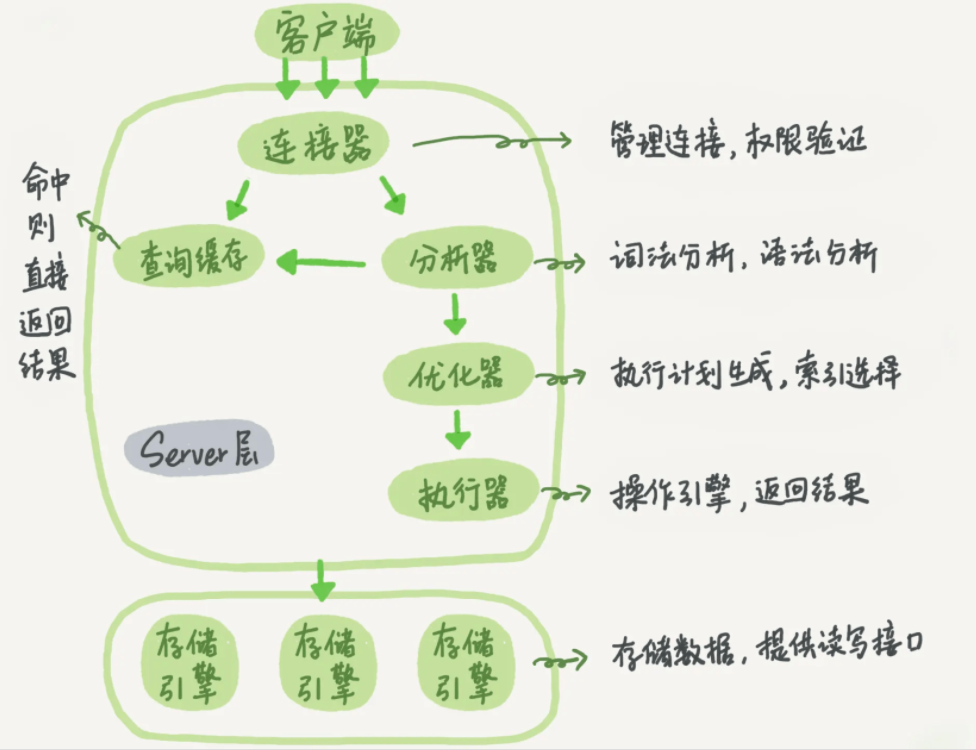
MySQL 可以分为 Server 层和存储引擎两大部分。
Server 层:
连接器查询缓存(MySQL 8.0 起废除)分析器优化器执行器
存储引擎:
负责数据的存储与提取插件式,支持多种存储引擎,如 InnoDB,MyISAM,MemoryInnoDB 是 MySQL 从 5.5.5 版本开始默认的存储引擎
接下来,我们从连接器开始,分析一条 SQL 语句的心路历程~
连接器#
连接器的作用有两个,第一是权限验证,第二是维持和管理连接。
我们通过命令:
mysql -h$ip -P$port -u$user -pCopy
来建立 MySQL 客户端与服务端的连接,输入密码后,如果验证通过,连接器会到权限表里查出你登陆的当前用户拥有的权限。
连接器的另一个功能是维持与管理连接。
客户端如果太长时间没有动静,连接器就会自动断开。这个时间是由参数 “wait_timeout” 控制的
使用命令:
show global variables like 'wait_timeout';Copy
显示连接的超时时间,单位为秒,换算结果为 8 小时:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+Copy
连接断开后,我们需要重新连接才可以发送命令。
长连接与短连接#
长连接是指如果客户端持续有请求,则一直使用同一个连接;短连接则是每次执行完很少的几次查询就断开连接,下次查询再重新建立一个连接。如下图所示:
因为建立一次连接的过程通常是比较复杂的,所以我们建议要尽量使用长连接;可是如果全部使用长连接,你可能会发现,MySQL 占用内存涨的特别快,这是因为,长连接占用资源,等断开连接后才会释放资源,随着时间推移会出现 OOM,现象就是服务重启了。解决方法有两种:
定期断开连接 MySQL 5.7 以后可以通过设置 “mysql_reset_connection” 来定期重置连接,以达到定期释放资源的目的
查询缓存#
连接建立完成后,执行逻辑就会来到第二步:查询缓存。
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 K-V 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。
你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。但是大多数情况下建议不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用,就被一个更新全部清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
MySQL 也提供了这种 “按需使用” 的方式。你可以将参数 “query_cache_type” 设置成 DEMAND,这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 “SQL_CACHE” 显式指定,像下面这个语句一样:
select SQL_CACHE * from T where ID=10;Copy
需要注意的是,MySQL 8.0 版本起就不再有查询缓存的功能。
分析器#
如果在查询缓存中没有命中,那么就会来到分析器。
分析器主要做两件事情:
词法分析语法分析
我们输入的是多个字符串和空格组成的一条 SQL 语句。所谓的 “词法分析” 就是,MySQL 需要识别里面字符串代表的含义,例如我们的查询语句:
select * from T where ID = 10;Copy
分析器会将 “select” 这个关键字识别为一条查询语句,将 “T” 识别成一个表名 ,将 “ID” 识别成一个查询字段等。
做完了这些识别工作,分析器就会做 “语法分析”。
分析器会通过词法分析的结果,通过语法规则判断你输入的这个 SQL 语句是否满足 MySQL 的语法。
优化器#
通过分析器的判断,MySQL 就知道你要做什么了。但是,在开始执行这条 SQL 语句前,还要经过优化器的处理。
优化器的功能顾名思义,就是对我们的 SQL 语句进行优化,当我们表中有多个索引的时候,优化器会决定使用哪一条索引;或者,在一个语句里面有多表关联(join)时,优化器会决定各个表的连接顺序,找出最优方案。
优化器的优化阶段完成后,这条 SQL 语句的执行方案就确定了。
执行器#
MySQL 通过分析器知道了你要做什么,通过优化器知道该怎么做,接下来就会进入执行器,执行语句。
开始执行的时候,执行器还是要先判断你对这个表 “T” 是否有执行查询的权限,如果没有,就会返回没有权限的错误(如果命中了查询缓存,会在查询缓存返回结果的时候做权限验证)。
如果有权限,就会打开表继续执行。打开表的时候,执行器会根据表的引擎定义,去使用这个引擎提供的接口。
我们的示例的表 “T” 中,ID 字段并没有建立索引,执行器的执行流程如下所示:
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
调用 InnoDB 引擎接口取 “下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中,所有满足条件的行组成的记录作为结果集返回给客户端。
对于有索引的表,执行逻辑也差不多。第一次调用的是 “取满足条件的第一行” 这个接口,之后循环取 “满足条件的下一行” 这个接口,这些接口都是引擎中已经定义好的;最后将满足条件的行记录作为结果集返回。
这就是执行一条 MySQL 查询语句,在 MySQL 内部发生的全过程。