
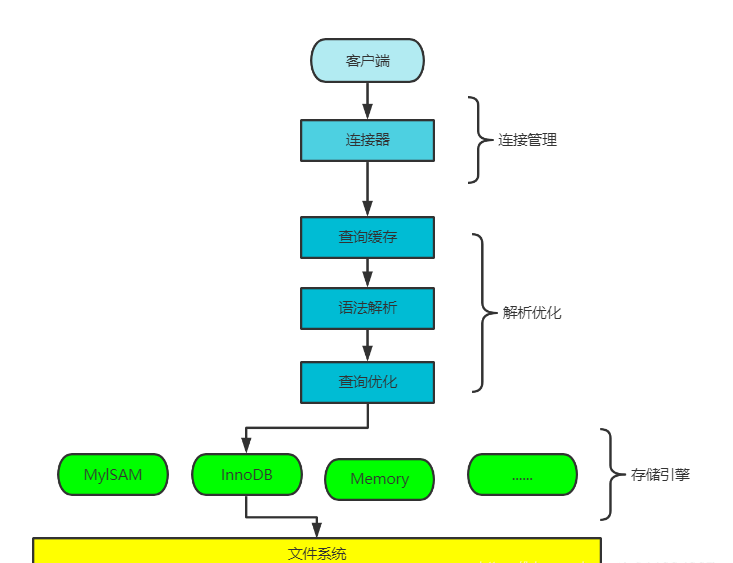
解析优化
1)查询缓存
mysql会把查询结果缓存起来,如果第二次同样的查询进来,就可以不去底层查询数据,直接从缓存中返回数据。
缓存不命中:两个查询只要有字符上的不一致就不命中,即使语意上是一样的(所以必须说完全一样的话,mysql才认为是一样的);查询缓存中包含了某些系统字段、用户自定义变量和函数、系统表,则也不会命中(例如now()函数,两次调用时间本身就不一样)。
缓存失效:缓存会监控涉及的每一张表,只要有表结构和数据被修改(update),则与该表有关的所有缓存全部失效。所以慎用缓存
2)语法解析
将受到的sql文本信息进行解析,提取信息,如涉及的表、条件等信息。
3)查询优化
收到语法解析后的查询信息后,对整个sql进行一定规则的优化,并生成执行计划,用户可以使用explain关键字查看。
存储引擎
mysql把数据的存储和提取操作都封装在了存储引擎中,存储引擎负责将数据存储在物理存储上,向我们表现出数据是存储为表中的一行数据(逻辑上)。
mysql在5.5.5版本后,默认使用的存储引擎为innoDB,在这之前默认使用的是mylsam
1)innodb和mylsam区别
1.支持事务的区别:innodb支持事务,mylsam不支持事务
2.支持外键的区别:innodb支持外键,mylsam不支持外键
3.数据存储方式:innodb主键的B+树的叶子检点存储的数据,辅助索引的叶子节点是主键;mylsam的B+树的叶子节点存储的都是数据的地址指针
4.innodb不存表的具体行数(支持事务,不同事务行数不同),count(*)需要全表扫描,mylsam用一个变量存储行数。
5.锁粒度:innodb存在表、行级锁,mylsam只有表级锁。
6.存储文件:innodb:frm存表定义文件,ibd是数据文件;mylsam:frm表定义文件,myd是数据文件,myi是索引文件。
4.常用语法(齐全)
库相关语法
//登陆
1.mysql -h ip -u root -p -P 3306
//创建库
2.create database 【if not exists】 库名 【character set 字符集名】;
//修改库
3.alter database 库名 character set 字符集名;
//删除库
4.drop database 【if exists】 库名;
//显示所有数据库
5.show databases
//选择数据库
6.use database_name
//执行sql文件
7.source test.sql
//查看系统字段
8.show variables like 'sql_mode'
//不使用缓存
9.set session query_cache_type = off
表相关语法
//创建表
1.create table 【if not exists】 表名(…字段名 字段类型 【约束】,...)
//查看表结构
2.desc table_name
//查看所有表
3.show tables
//添加列
4.alter table 表名 add column 列名 类型 【first|after 字段名】;
//修改列类型&约束
5.alter table 表名 modify column 列名 新类型 【新约束】;
//修改列名称
6.alter table 表名 change column 旧列名 新列名 类型;
//删除列
7.alter table 表名 drop column 列名;
//修改表名
8.alter table 表名 rename 【to】 新表名;
//删除表
9.drop table【if exists】 表名;
//复制表
10.create table 表名 like 旧表;
//复制表结构&数据
11.create table 表名 select 查询列表 from 旧表【where 筛选】;